Introduction
简介
HBase is a high-performance, distributed NoSQL key-value store built on top of Hadoop Distributed File System (HDFS). It is designed for high-throughput, low-latency read/write access to large datasets and is implemented in Java. HBase is optimized for real-time data processing on a massive scale.
HBase 是一个高性能、分布式的 NoSQL 键值存储系统,构建在 Hadoop 分布式文件系统 (HDFS) 之上。它旨在为大型数据集提供高吞吐量、低延迟的读/写访问,并采用 Java 实现。HBase 针对大规模实时数据处理进行了优化。
Hive, on the other hand, offers a SQL-like interface called HiveQL for performing analytical queries on large datasets. While Hive was originally built on top of HDFS, it can be integrated with HBase to leverage the strengths of both systems.
另一方面,Hive 提供了一个名为 HiveQL 的类 SQL 接口,用于对大型数据集执行分析查询。虽然 Hive 最初也是构建在 HDFS 之上的,但它可以与 HBase 集成,以利用两个系统的优势。
Hive-HBase Integration
Hive-HBase 集成
Hive provides a Storage Handler mechanism, which allows it to interface with HBase through the class HBaseStorageHandler. This integration allows Hive to:
Hive 提供了一种存储处理器 (Storage Handler) 机制,使其能够通过 HBaseStorageHandler 类与 HBase 进行交互。这种集成允许 Hive 进行以下操作:
- Create and manage HBase tables directly using Hive DDL statements.
- 直接使用 Hive DDL 语句创建和管理 HBase 表。
- Synchronize table definitions across the Hive Metastore and HBase catalog.
- 在 Hive Metastore 和 HBase 目录之间同步表定义。
- Query HBase tables using HiveQL, enabling SQL-like access to NoSQL data.
- 使用 HiveQL 查询 HBase 表,实现对 NoSQL 数据类 SQL 方式的访问。
Why Use Hive with HBase?
为什么将 Hive 与 HBase 结合使用?
The integration of Hive and HBase offers several advantages, particularly for analytics and real-time data processing:
Hive 和 HBase 的集成具有多项优势,特别是在分析和实时数据处理方面:
- SQL-like querying on HBase: Use HiveQL to query HBase data, making it easier for analysts familiar with SQL to access NoSQL data.
- 对 HBase 进行类 SQL 查询:使用 HiveQL 查询 HBase 数据,使熟悉 SQL 的分析师能够更轻松地访问 NoSQL 数据。
- Real-time data analysis: Leverage the low-latency performance of HBase for real-time big data analysis.
- 实时数据分析:利用 HBase 的低延迟性能进行实时大数据分析。
- Complex queries: Execute advanced analytical operations, such as GROUP BY, JOIN, and ORDER BY on HBase data.
- 复杂查询:在 HBase 数据上执行高级分析操作,例如 GROUP BY、JOIN 和 ORDER BY。
- Combining strengths: Hive’s batch-processing capabilities complement HBase’s scalable, low-latency storage, providing a powerful solution for large-scale analytics.
- 结合优势:Hive 的批处理能力与 HBase 的可扩展、低延迟存储相辅相成,为大规模分析提供了强大的解决方案。
Real-time data often resides in HBase, but direct analysis can be difficult. Hive bridges this gap, providing richer analytical capabilities to query and process this data.
实时数据通常驻留在 HBase 中,但直接分析可能比较困难。Hive 弥补了这一差距,为查询和处理这些数据提供了更丰富的分析能力。
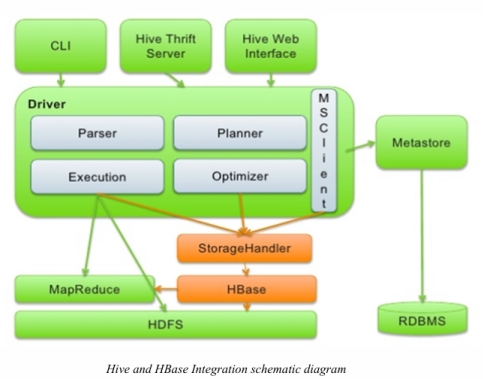
Hive Integrates HBase Principles
Hive 集成 HBase 的原理
The integration between Hive and HBase is primarily facilitated through Hive’s Storage Handler mechanism. The handler used for this integration is the hive-hbase-handler JAR, which allows for smooth communication between Hive and HBase via external APIs.
Hive 与 HBase 之间的集成主要是通过 Hive 的存储处理器 (Storage Handler) 机制实现的。用于此集成的处理器是 hive-hbase-handler JAR 包,它允许 Hive 和 HBase 通过外部 API 进行平滑通信。
The key class for this integration is: org.apache.hadoop.hive.hbase.HBaseStorageHandler
该集成的核心类是:org.apache.hadoop.hive.hbase.HBaseStorageHandler
This handler allows Hive DDL statements to manage table definitions in both the Hive Metastore and the HBase catalog simultaneously, ensuring consistency across both systems.
该处理器允许 Hive DDL 语句同时管理 Hive Metastore 和 HBase 目录中的表定义,从而确保两个系统之间的一致性。
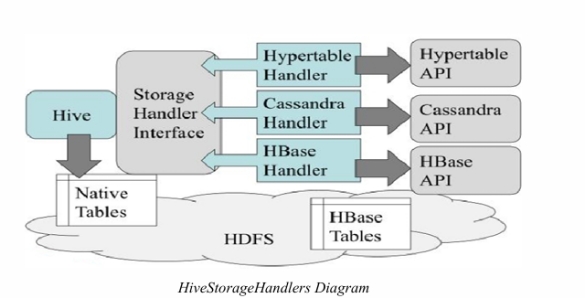
Hive Storage Handlers
Hive 存储处理器
The HiveStorageHandler interface is used to connect Hive to various external storage systems, including NoSQL databases like HBase and Cassandra.
HiveStorageHandler 接口用于将 Hive 连接到各种外部存储系统,包括 HBase 和 Cassandra 等 NoSQL 数据库。
A Storage Handler is responsible for defining the following:
存储处理器 (Storage Handler) 负责定义以下内容:
- InputFormat: How data is read from the external storage system.
- 输入格式 (InputFormat):如何从外部存储系统读取数据。
- OutputFormat: How data is written to the external storage system.
- 输出格式 (OutputFormat):如何将数据写入外部存储系统。
- SerDe: How data is serialized and deserialized in Hive.
- 序列化与反序列化 (SerDe):数据在 Hive 中如何进行序列化和反序列化。
By using Storage Handlers, Hive can read from and write to NoSQL systems like HBase. This enables users to run SQL-like queries on NoSQL data and perform actions like generating reports.
通过使用存储处理器,Hive 可以对 HBase 等 NoSQL 系统进行读写操作。这使得用户能够在 NoSQL 数据上运行类 SQL 查询,并执行生成报告等操作。
Performance Considerations
性能考量
While Hive provides a convenient way to query HBase, there are performance trade-offs to consider:
虽然 Hive 提供了一种查询 HBase 的便捷方式,但也需要考虑性能折衷:
- Network Overhead: Queries over NoSQL systems (like HBase) often incur higher latency compared to Hive queries on HDFS. This is due to the additional network socket overhead when making remote calls to the database server.
- 网络开销 (Network Overhead):与 HDFS 上的 Hive 查询相比,在 NoSQL 系统(如 HBase)上的查询通常具有更高的延迟。这是由于在向数据库服务器发起远程调用时存在额外的网络套接字开销。
- Multiple File Merges in HBase: HBase may need to merge multiple underlying storage files (HFiles) during read operations, which can affect performance.
- HBase 中的多文件合并 (Multiple File Merges in HBase):HBase 在读取操作期间可能需要合并多个底层的存储文件 (HFile),这可能会影响性能。
- Sequential I/O: Unlike HDFS, which is optimized for sequential reads, NoSQL systems like HBase are not optimized for this type of operation, leading to potential performance bottlenecks.
- 顺序 I/O (Sequential I/O):与针对顺序读取进行了优化的 HDFS 不同,HBase 等 NoSQL 系统并未针对此类操作进行优化,从而可能导致性能瓶颈。
Properties
相关属性
- STORED BY ‘org.apache.hadoop.hive.hbase.HBaseStorageHandler’
- Define hive table to use HBaseStorageHandler
- 定义 Hive 表以使用 HBaseStorageHandler
- SERDEPROPERTIES : - hive can understand hbase table
- SERDEPROPERTIES:使 Hive 能够理解 HBase 表
- hbase.columns.mapping
- map HBase Column (column qualifier) with hive Column.
- hbase.columns.mapping:将 HBase 列(列限定符)映射到 Hive 列。
- TBLPROPERTIES
- “hbase.table.name” = “emp”
- map hive table with HBase table.
- 将 Hive 表与 HBase 表建立映射关系。