Chapter 4
第 4 章
Kafka is comparable to traditional messaging systems such as P2P, ActiveMQ.
Kafka 可与传统的各种消息系统(如 P2P、ActiveMQ)相媲美。
Once the consumer subscribes to topics, the poll loop handles all details of A. coordination, B. partition rebalances, C. heartbeats.
一旦消费者订阅了主题,poll 循环就会处理 A. 协调,B. 分区再平衡,C. 心跳的所有细节。
The offsets are committed after the message has been processed.
偏移量(Offsets)是在消息被处理后提交的。
If the processing goes wrong, then the message will be read again by the consumer.
如果处理过程中出现错误,消费者将再次读取该消息。
It results in duplicate processing of the messages. “At least once” delivery semantics must be used.
这会导致消息的重复处理。必须使用 “至少一次”(At least once)的交付语义。
Subscribe() method accepts “Single topic name”, “Multiple topic names” and “Regex expression”.
Subscribe() 方法接受 “单主题名称”、”多主题名称” 和 “正则表达式”。
A Consumer Group can be described as a single logical consumer that subscribes to a set of topics which points to application.
消费者组(Consumer Group)可以被描述为一个订阅了一组指向应用程序的主题的单一逻辑消费者。
Kafka stores the offsets at which a consumer group has been reading.
Kafka 存储消费者组读取到的偏移量。
The committed offsets store in a Kafka topic named __consumer_offsets.
已提交的偏移量存储在一个名为 __consumer_offsets 的 Kafka 主题中。
Steps in sequence to read message:
读取消息的顺序步骤:
A. Create consumer properties.
A. 创建消费者属性。
B. Create a consumer.
B. 创建一个消费者。
C. Subscribe the consumer to a specific topic.
C. 将消费者订阅到特定主题。
D. Poll for some new data.
D. 轮询(Poll)一些新数据。
E. Iterate through Consume records.
E. 遍历消费记录。
The group.id property defines a unique identity for the set of consumers within the same consumer group.
group.id 属性为同一消费者组内的一组消费者定义了一个唯一的标识。
The Client.id value is specified by the Kafka consumer client and is used to distinguish between different clients.
Client.id 值由 Kafka 消费者客户端指定,用于区分不同的客户端。
Producer pushes data to Kafka broker then consumer pull data from Kafka broker.
生产者将数据推送到 Kafka 代理(Broker),然后消费者从 Kafka 代理拉取数据。
Consumer client uses the poll method to poll for data from the subscribed topic partition.
消费者客户端使用 poll 方法从订阅的主题分区轮询数据。
The return type of the poll method is ConsumerRecords.
poll 方法的返回类型是 ConsumerRecords。
poll() method will a consumer use to consume records from the subscribed topic by this consumer.
消费者将使用 poll() 方法来消费该消费者订阅的主题中的记录。
In Kafka 2.x, the offset for a topic partition is stored in a Kafka topic.
在 Kafka 2.x 中,主题分区的偏移量存储在 Kafka 主题中。
All consumers that connect to the same Kafka cluster and use the same group.id form a Consumer Group.
连接到同一个 Kafka 集群并使用相同 group.id 的所有消费者组成一个消费者组。
acks is not a Kafka consumer configuration.
acks 不是 Kafka 消费者的配置。
A Kafka consumer is an application that can read data in a Kafka cluster.
Kafka 消费者是一个可以读取 Kafka 集群中数据的应用程序。
A consumer can consume messages from one or more Kafka topics.
一个消费者可以消费一个或多个 Kafka 主题的消息。
Kafka Consumer is used for optimal consumption of Kafka data.
Kafka 消费者用于优化 Kafka 数据的消费。
The primary role of a Kafka consumer is to take Kafka connection and consumer properties to read records from the appropriate Kafka broker.
Kafka 消费者的主要作用是利用 Kafka 连接和消费者属性,从适当的 Kafka 代理读取记录。
Complexities of concurrent application consumption, offset management, delivery semantics, and a lot more are taken care of by Consumer APIs.
并发应用程序消费、偏移量管理、交付语义等许多复杂性都由消费者 API 处理。
These are the steps to create a Kafka consumer:
以下是创建 Kafka 消费者的步骤:
A. Create a Java Class Consumer Demo.java
A. 创建一个 Java 类 Consumer Demo.java
B. Create the consumer properties.
B. 创建消费者属性。
C. Create a consumer.
C. 创建一个消费者。
D. Subscribe the consumer to a specific topic.
D. 将消费者订阅到特定主题。
E. Create a Poll loop to receive data.
E. 创建一个轮询(Poll)循环以接收数据。
Here, we will list the required properties of a consumer:
在这里,我们将列出消费者所需的属性:
key.deserializer: It is a Deserializer class for the key, which is used to implement the org.apache.kafka.common.serialization.Deserializer interface.
key.deserializer:这是键(key)的反序列化类,用于实现 org.apache.kafka.common.serialization.Deserializer 接口。
value.deserializer: A Deserializer class for value which implements the org.apache.kafka.common.serialization.Deserializer interface.
value.deserializer:值的反序列化类,实现了 org.apache.kafka.common.serialization.Deserializer 接口。
bootstrap.servers: It is a list of host and port pairs that are used to establish an initial connection with the Kafka cluster.It does not contain the full set of servers that a client requires. Only the servers which are required for bootstrapping are required.
bootstrap.servers:这是一个主机和端口对的列表,用于建立与 Kafka 集群的初始连接。它不包含客户端所需的全部服务器集合。只需要用于引导(bootstrapping)的服务器。
group.id: It is a unique string that identifies the consumer of a consumer group.
group.id:这是一个唯一的字符串,用于标识消费者组中的消费者。
auto.offset.reset: This property is required when no initial offset is present or if the current offset does not exist anymore on the server.
auto.offset.reset:当没有初始偏移量或服务器上不再存在当前偏移量时,需要此属性。
There are the following values used to reset the offset values:
以下用于重置偏移量的值:
earliest: This offset variable automatically resets the value to its earliest offset.
earliest:此偏移量变量自动将值重置为最早的偏移量。
latest: This offset variable reset the offset value to its latest offset.
latest:此偏移量变量将偏移量值重置为最新的偏移量。
none: If no previous offset is found for the previous group, it throws an exception to the consumer.
none:如果未找到前一个组的先前偏移量,则向消费者抛出异常。
Subscribe the consumer to a specific topic
将消费者订阅到特定主题
To read the messages from a topic, we need to connect the consumer to the specified topic.Here, we use Arrays.asList() as it allows our consumer to subscribe to multiple topics.
要从主题读取消息,我们需要将消费者连接到指定的主题。在这里,我们要使用 Arrays.asList(),因为它允许我们的消费者订阅多个主题。
Below code shows the implementation of subscription of the consumer to one topic:
下面的代码展示了消费者订阅一个主题的实现:
1 | consumer.subscribe(Arrays.asList(topic)); |
Poll for some new data
轮询一些新数据
The consumer reads data from Kafka through the polling method.
消费者通过轮询方法从 Kafka 读取数据。
The poll method returns the data that hasn’t been fetched yet by the consumer subscribed to the partitions.
poll 方法返回订阅了分区的消费者尚未获取的数据。
The duration of the poll call for example .poll(Duration.ofMillis(100)) is the amount of time to block on this call before returning an empty list in case no data was returned (also called long polling).
轮询调用的持续时间,例如 .poll(Duration.ofMillis(100)),是在没有数据返回的情况下(也称为长轮询),在返回空列表之前此调用阻塞的时间量。
Java Consumers inside a Consumer Group
消费者组内的 Java 消费者
We have seen that consumers can share reads in a Consumer Group in order to scale.We can achieve this using the CLI, and of course using Java.
我们已经看到,消费者可以在消费者组中共享读取操作以进行扩展。我们可以使用 CLI 来实现这一点,当然也可以使用 Java。
Partition Rebalance - Groups
分区再平衡 - 组
Moving partition ownership from one consumer to another is called a rebalance.Rebalances are important because they provide the consumer group with high availability and scalability.
将分区所有权从一个消费者移动到另一个消费者称为再平衡(rebalance)。再平衡非常重要,因为它们为消费者组提供了高可用性和可扩展性。
Currently, we only have one consumer in our group, and therefore that consumer reads from all the topic partitions.
目前,我们的组中只有一个消费者,因此该消费者读取所有主题分区。
Automatic Offset Committing Strategy
自动偏移量提交策略
Using the Kafka Consumer Java API, offsets are committed regularly and automatically in order to enable at-least-once reading scenarios.
使用 Kafka Consumer Java API,偏移量会定期自动提交,以实现至少一次(at-least-once)的读取场景。
You can get a refresher on Consumer Offsets here.
你可以在这里复习消费者偏移量(Consumer Offsets)的相关内容。
By default, the property enable.auto.commit=true and therefore offsets are committed automatically with a frequency controlled by the config auto.commit.interval.ms.
默认情况下,属性 enable.auto.commit=true,因此偏移量会根据配置 auto.commit.interval.ms 控制的频率自动提交。
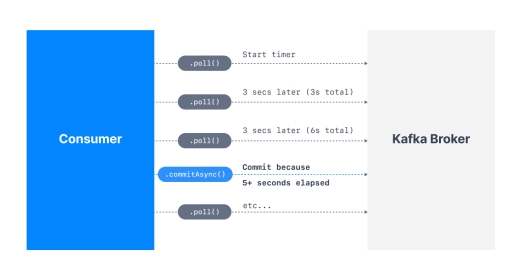
The process of committing the offsets happens when the .poll() function is called and the time between two calls to .poll() is greater than the setting auto.commit.interval.ms (5 seconds by default).
提交偏移量的过程发生在调用 .poll() 函数时,并且两次调用 .poll() 之间的时间大于设置 auto.commit.interval.ms(默认为 5 秒)。
This means that to be in an “at-least-once” processing use case (the most desirable one), you need to ensure all the messages in your consumer code are successfully processed before performing another .poll() call.(which is the case in the sample code defined above).If this is not the case, then offsets could be committed before the messages are actually processed, therefore resulting in an “at-most once” processing pattern, possibly resulting in message skipping (which is undesirable).
这意味着要处于 “至少一次” 处理用例(最理想的情况),你需要确保在执行另一次 .poll() 调用之前,消费者代码中的所有消息都已成功处理。(上面定义的示例代码就是这种情况)。如果情况并非如此,那么偏移量可能会在消息实际被处理之前提交,从而导致 “至多一次”(at-most once)的处理模式,可能导致消息跳过(这是不可取的)。
In that (rare) case, you must disable enable.auto.commit, and most likely move processing to a separate thread, and then from time to time call .commitSync() or .commitAsync() with the correct offsets manually.
在这种(罕见)情况下,你必须禁用 enable.auto.commit,并且很可能将处理移动到单独的线程,然后不时手动调用带有正确偏移量的 .commitSync() 或 .commitAsync()。
This complicated use case is discussed in the Kafka Consumer Documentation under the section “Automatic Offset Committing”.
这个复杂的用例在 Kafka 消费者文档的 “Automatic Offset Committing”(自动偏移量提交)部分进行了讨论。
Graceful Shutdown of Consumer (addShutdownHook())
消费者的优雅关闭 (addShutdownHook())
Currently our consumer is running an infinite loop with while(true) but we can catch an Exception that happens when our consumer is shutting down.
目前我们的消费者正在运行一个带有 while(true) 的无限循环,但我们可以捕获消费者关闭时发生的异常。
For this, we need to call consumer.wakeup() which will trigger a WakeupException next time the .poll() function is called.
为此,我们需要调用 consumer.wakeup(),这将在下次调用 .poll() 函数时触发 WakeupException。
The WakeupException itself does not need to be handled, but then in a finally{} block we can call consumer.close() which will take care of:
WakeupException 本身不需要处理,但在 finally{} 块中,我们可以调用 consumer.close(),它将负责:
Committing the offsets if needed.
如果需要,提交偏移量。
Close the connection to Kafka.
关闭与 Kafka 的连接。
In order to call consumer.wakeup() we need to use a ShutdownHook.
为了调用 consumer.wakeup(),我们需要使用 ShutdownHook。
That ShutdownHook needs to be linked to the main thread in order to wait for all threads to complete before shutting down the program.
该 ShutdownHook 需要链接到主线程,以便在关闭程序之前等待所有线程完成。