Chapter 1
第 1 章
Topic: a topic is like a category/an index, it groups messages together.
Topic:主题就像一个类别或索引,它将消息分组在一起。
Producer: processes that push messages to Kafka topics.
Producer:向 Kafka 主题推送消息的进程。
Consumer: processes that consume messages from Kafka topics.
Consumer:从 Kafka 主题消费消息的进程。
Partition: an immutable sequence of topic messages that is continually appended to a structured commit log.
Partition:主题消息的不可变序列,它被不断地追加到结构化的提交日志中。
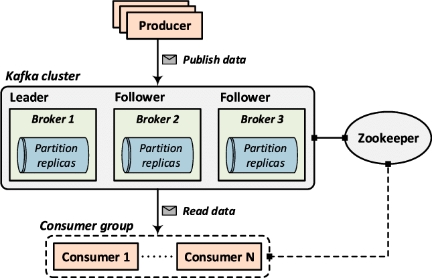
Kafka broker: one or more servers that form a Kafka cluster.
Kafka broker:组成 Kafka 集群的一台或多台服务器。
Consumer Groups: these are groups of consumers that are used to load share. If a consumer group is consuming messages from one partition, each consumer in a consumer group will consume a different message. Consumer groups are typically used to load share.
Consumer Groups:这是用于负载分担的消费者组。如果一个消费者组正在从一个分区消费消息,该组中的每个消费者将消费不同的消息。消费者组通常用于负载分担。
Queue is a first-in-first-out (FIFO) linear table data structure. You can use an array or a linked list to implement a queue. A queue needs to maintain two pointers, the head points to the head of the queue, and the tail points to the tail of the queue. Move the end of the queue to add elements (enqueue), move the head pointer to delete elements (dequeue).
Queue(队列)是一种先进先出 (FIFO) 的线性表数据结构。你可以使用数组或链表来实现队列。队列需要维护两个指针,头部指向队列的头,尾部指向队列的尾。移动队列的尾部以添加元素(入队),移动头部指针以删除元素(出队)。
Publish/subscribe messaging is a pattern that is characterized by the sender (publisher) of a piece of data (message) not specifically directing it to a receiver.
发布/订阅消息传递是一种模式,其特征在于数据(消息)的发送者(发布者)并不专门将其指向特定的接收者。
The process that pushes the messages to kafka topic is Producer.
将消息推送到 Kafka 主题的进程是 Producer。
Multiple Producers, Multiple Consumers, High Performance makes Kafka a Good Choice over the Traditional Message brokers.
多生产者、多消费者和高性能使得 Kafka 成为优于传统消息代理的不错选择。
Message brokers are used for decoupling data processing from data producers.
消息代理用于将数据处理与数据生产者解耦。
Log Aggregation process of collecting physical log files from servers and putting them in a central place (a file server or HDFS) for processing.
日志聚合是从服务器收集物理日志文件并将其放置在中心位置(文件服务器或 HDFS)进行处理的过程。
Kafka was released as an open-source project on GitHub in 2010.
Kafka 于 2010 年作为开源项目在 GitHub 上发布。
Messages in Kafka are categorized into topics.
Kafka 中的消息被归类为 topics(主题)。
The advanced clients use producers and consumers has building blocks and provide higher-level functionality on top.
高级客户端使用生产者和消费者作为构建块,并在其之上提供更高级的功能。
A key feature of Apache Kafka is that of retention, which is the durable storage of messages for some period of time.
Apache Kafka 的一个关键特性是保留(retention),即消息在一段时间内的持久存储。
Kafka brokers are configured with a default retention setting for topics, either retaining messages for some period of time (e.g., 7 days) or until the topic reaches a certain size in bytes (e.g., 1 GB).
Kafka broker 配置有 topics 的默认保留设置,要么保留消息一段时间(例如 7 天),要么保留直到主题达到特定的大小(例如 1 GB)。
Consumers work as part of a consumer group, which is one or more consumers that work together to consume a topic.
消费者作为 consumer group(消费者组)的一部分工作,消费者组是一个或多个协同工作以消费主题的消费者。
Kafka cluster responds to a rapidly growing large amount of data to scale horizontally. For handling very large message streams Producers can be scaled, Consumers can be scaled, and Brokers can be scaled.
Kafka 集群通过水平扩展来响应快速增长的大量数据。为了处理非常大的消息流,Producers 可以扩展,Consumers 可以扩展,Brokers 也可以扩展。
Apache Kafka provides the circulatory system for the data ecosystem.
Apache Kafka 为数据生态系统提供了循环系统。
Apache Kafka carries messages between the various members of the infrastructure, providing a consistent interface for all clients.
Apache Kafka 在基础设施的各个成员之间传递消息,为所有客户端提供一致的接口。
Consumer Offset is not a component of Kafka.
Consumer Offset(消费者偏移量)不是 Kafka 的组件。
The broker receives messages from producers, assigns offsets to them, and commits the messages to storage on disk.
Broker 接收来自生产者的消息,为它们分配偏移量,并将消息提交到磁盘存储。
In Kafka, producers and consumers are fully decoupled and agnostic of each other.
在 Kafka 中,生产者和消费者是完全解耦的,并且彼此互不知晓。
In Kafka, messages are organized and durably stored in topics.
在 Kafka 中,消息被组织并持久存储在 topics 中。
Topics are partitioned, meaning a topic is spread over a number of “buckets” located on different Kafka brokers.
Topics 是分区的,这意味着一个主题分布在位于不同 Kafka broker 上的多个“桶”中。
Message with the same key are written to the same topic partition.
具有相同键(Key)的消息被写入同一个主题分区。
To make your data fault-tolerant and highly-available, every topic can be replicated.
为了使数据具有容错性和高可用性,每个主题都可以被复制。
Messages and Batches
消息与批次
Kafka supports the compression of batches of messages with an efficient batching format. A batch of messages can be compressed and sent to the server, and this batch of messages is written in compressed form and will remain compressed in the log. The batch will only be decompressed by the consumer.
Kafka 支持使用高效的批处理格式压缩消息批次。一批消息可以被压缩并发送到服务器,这批消息以压缩形式写入,并将保持压缩状态存储在日志中。该批次仅在消费者端解压缩。
Topics and Partitions
主题与分区
Topic groups related events together and durably stores them. The closest analogy for a Kafka topic is a table in a database or folder in a file system.
主题将相关事件分组在一起并持久存储它们。Kafka 主题最接近的类比是数据库中的表或文件系统中的文件夹。
Topics are the central concept in Kafka that decouples producers and consumers. A consumer pulls messages off of a Kafka topic while producers push messages into a Kafka topic. A topic can have many producers and many consumers.
Topics 是 Kafka 中解耦生产者和消费者的核心概念。消费者从 Kafka 主题拉取消息,而生产者将消息推送到 Kafka 主题。一个主题可以有许多生产者和许多消费者。
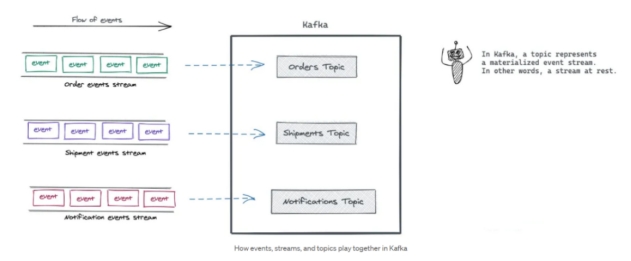
In Kafka, a topic represents a materialized event stream. In other words, a stream at rest.
在 Kafka 中,主题代表具体化的事件流。换句话说,是静态的流。
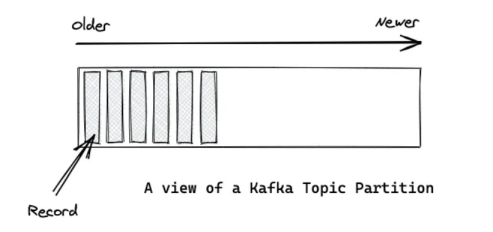
Kafka’s topics are divided into several partitions. While the topic is a logical concept in Kafka, a partition is the smallest storage unit that holds a subset of records owned by a topic. Each partition is a single log file where records are written to it in an append-only fashion.
Kafka 的主题分为几个分区。虽然主题在 Kafka 中是一个逻辑概念,但 partition 是最小的存储单元,保存着主题拥有的一部分记录。每个分区都是一个单独的日志文件,记录以仅追加的方式写入其中。
Producers and Consumers
生产者与消费者
Producers are those client applications that publish (write) events to Kafka, and consumers are those that subscribe to (read and process) these events.
Producers 是那些向 Kafka 发布(写入)事件的客户端应用程序,而 consumers 是那些订阅(读取和处理)这些事件的应用程序。
Brokers and Clusters
Broker 与集群
Kafka with more than one broker is called Kafka Cluster. It can be expanded and used without downtime. Apache Kafka Clusters are used to manage the persistence and replication of messages of data, so if the primary cluster goes down, other Kafka Clusters can be used to deliver the same service without any delay.
拥有多个 broker 的 Kafka 称为 Kafka Cluster(集群)。它可以扩展并在不停机的情况下使用。Apache Kafka 集群用于管理数据消息的持久性和复制,因此如果主集群宕机,其他 Kafka 集群可以用于提供相同的服务而没有任何延迟。