Chapter 5
第5章
Spark Job Introduction
Spark 作业介绍
The transformation function of Spark RDD will not perform any action, and when Spark is executing the action function of RDD, RDD lineage graph is created automatically as we apply transformation(logical DAG).
Spark RDD 的转换函数不会执行任何动作,当 Spark 执行 RDD 的动作函数时,随着我们应用转换(逻辑 DAG),会自动创建 RDD 血统图。
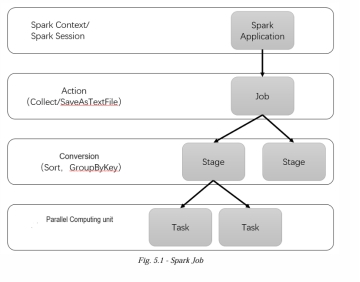
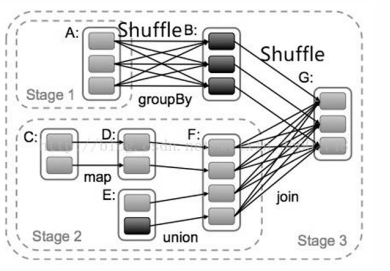
the Spark scheduler (DAG Scheduler) will construct the execution graph (graph) and Start a Spark job (Job). The job is composed of many stages, which are the steps required to realize the final RDD data in the conversion. Each stage consists of a set of tasks that are calculated in parallel on an executor.
Spark 调度器(DAG 调度器)将构建执行图(graph)并启动一个 Spark 作业(Job)。该作业由许多阶段(Stage)组成,这些阶段是转换中实现最终 RDD 数据所需的步骤。每个阶段包含一组在执行器上并行计算的任务。
DAG
DAG(有向无环图)
Directed – the data flows in 1 direction (step -> next step)
有向 (Directed) – 数据向一个方向流动(步骤 -> 下一步骤)
Acyclic – No loop (data never goes back to previous step)
无环 (Acyclic) – 无循环(数据从不回流到上一步骤)
Graph – It’s a network of steps
图 (Graph) – 它是步骤的网络
At the high level of Spark task scheduling, Spark will build a Directed Acyclic Graph (DAG) for each Job based on the RDD dependencies. In Spark, this is called DAG Scheduler.
在 Spark 任务调度的高层级,Spark 会根据 RDD 依赖关系为每个作业构建有向无环图(DAG)。在 Spark 中,这被称为 DAG 调度器。
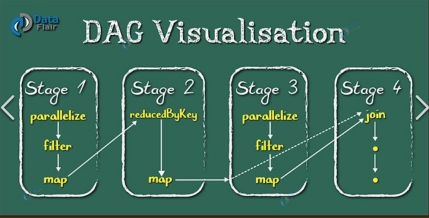
Why DAG?
为什么要用 DAG?
- Which steps must happen first
- 哪些步骤必须先发生
- Which steps can run in parallel
- 哪些步骤可以并行运行
- Where shuffle required
- 哪里需要 Shuffle(洗牌/混洗)
- How to split work into stages and tasks.
- 如何将工作拆分为阶段和任务。
Spark Scheduler 2 components
Spark 调度器的 2 个组件
Key Concepts:
关键概念:
DAG Scheduler:
DAG 调度器:
Role: The DAG Scheduler is responsible for taking the RDD lineage then Splitting the job into stages at shuffle boundaries, create a stage graph (execution DAG) and sending stages to the Task Scheduler.
角色:DAG 调度器负责获取 RDD 血统,然后在 Shuffle 边界处将作业拆分为多个阶段,创建阶段图(执行 DAG),并将阶段发送给任务调度器(Task Scheduler)。
Stage Graph: The stage graph consists of stages, where each stage contains tasks that can be executed in parallel. Stages are determined by shuffle dependencies—each stage boundary is where data shuffling happens between RDDs.
阶段图:阶段图由阶段组成,其中每个阶段包含可以并行执行的任务。阶段由 Shuffle 依赖关系决定——每个阶段的边界是 RDD 之间发生数据 Shuffle 的地方。
Stage Dependencies: Within a stage, all tasks run independently and in parallel. Between stages, tasks depend on the output of previous stages.
阶段依赖:在一个阶段内,所有任务独立且并行运行。在阶段之间,任务依赖于前一阶段的输出。
TaskScheduler:
任务调度器 (TaskScheduler):
Role: The TaskScheduler is responsible for launching tasks on the cluster’s worker nodes. It receives tasks from the DAG Scheduler and assigns them to executors.
角色:任务调度器负责在集群的工作节点上启动任务。它从 DAG 调度器接收任务并将它们分配给执行器。
Task Execution: TaskScheduler handles the scheduling of tasks, monitors their execution, and deals with failures. It ensures that tasks are distributed and run across the available cluster resources.
任务执行:任务调度器处理任务的调度,监控它们的执行,并处理故障。它确保任务在可用的集群资源上分布和运行。
Data Locality: TaskScheduler tries to place tasks on executors where the data already exists to reduce network transfer.
数据本地性:任务调度器尝试将任务放置在数据已经存在的执行器上,以减少网络传输。
Stages and Tasks
阶段和任务
Stages: A stage in Spark is a collection of tasks that can be executed together. Stages are separated by shuffle operations.
阶段 (Stages):Spark 中的阶段是可以一起执行的任务集合。阶段由 Shuffle 操作分隔。
Tasks: The smallest unit of work in Spark, which operates on a single partition of an RDD. There are two types of tasks:
任务 (Tasks):Spark 中最小的工作单元,它对 RDD 的单个分区进行操作。有两种类型的任务:
ShuffleMapTask: Produces intermediate results that will be shuffled to the next stage (prepare it for shuffle).
ShuffleMapTask:产生中间结果,这些结果将被 Shuffle 到下一个阶段(为 Shuffle 做准备)。
reduceByKey(), groupByKey()
(例如:reduceByKey(), groupByKey())
ResultTask: Produces the final result of a stage, which is returned to the driver.
ResultTask:产生阶段的最终结果,该结果将返回给驱动程序 (Driver)。
Collect(), saveAsTextFile()
(例如:Collect(), saveAsTextFile())
How DAG Scheduler Works
DAG 调度器如何工作
1. Job Submission:
1. 作业提交:
When an action (e.g., count(), collect()) is called on an RDD, Spark submits a job.
当在 RDD 上调用动作(例如 count(), collect())时,Spark 会提交一个作业。
driver program initializes the SparkContext.
驱动程序初始化 SparkContext。
2. Building the DAG:
2. 构建 DAG:
The DAG Scheduler analyzes the RDD lineage to build a DAG of stages. Each stage represents a set of transformations that can be executed without shuffling data.
DAG 调度器分析 RDD 血统以构建阶段的 DAG。每个阶段代表一组可以在不 Shuffle 数据的情况下执行的转换。
3. Stage Creation:
3. 阶段创建:
The DAG Scheduler creates stages by identifying shuffle boundaries. A new stage is created for each shuffle operation. Stages are composed of tasks that operate on partitions of the RDD.
DAG 调度器通过识别 Shuffle 边界来创建阶段。每个 Shuffle 操作都会创建一个新阶段。阶段由对 RDD 分区进行操作的任务组成。
When a ShuffleDependency is encountered, a new stage is created.
当遇到 ShuffleDependency 时,会创建一个新阶段。
When a NarrowDependency is encountered, the operations are added to the current stage.
当遇到 NarrowDependency(窄依赖)时,操作会被添加到当前阶段。
The number of tasks in each stage is determined by the number of partitions in the last RDD of that stage.
每个阶段中的任务数量由该阶段最后一个 RDD 的分区数量决定。
4. Task Scheduling:
4. 任务调度:
The DAG Scheduler submits tasks to the TaskScheduler, which schedules them on executors across the cluster.
DAG 调度器将任务提交给任务调度器,任务调度器将它们调度到集群中的执行器上。
5. Execution and Monitoring:
5. 执行和监控:
Tasks are executed on worker nodes, and the TaskScheduler monitors their progress. If tasks fail, the TaskScheduler retries them according to the configured retry policy.
任务在工作节点上执行,任务调度器监控它们的进度。如果任务失败,任务调度器会根据配置的重试策略重试它们。
6. Result Collection:
6. 结果收集:
Once all tasks in a stage complete successfully, the results are collected and used as input for the next stage until the final action is completed.
一旦阶段中的所有任务成功完成,结果将被收集并用作下一个阶段的输入,直到最终动作完成。
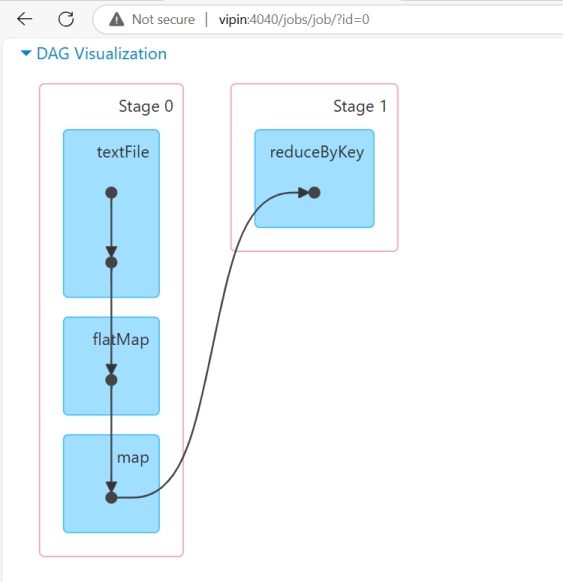
Click Me to See how DAG Scheduler works
Spark deployment architecture
Spark 部署架构
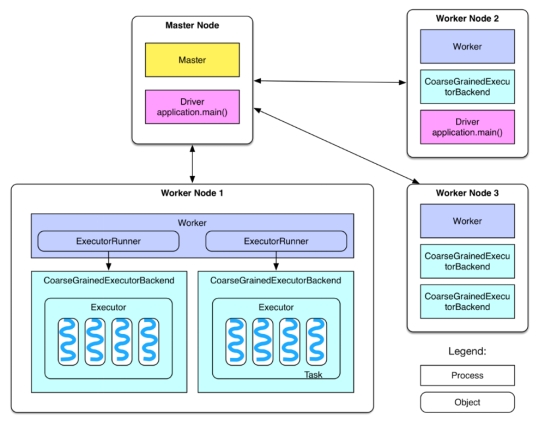
Cluster Overview
集群概览
Cluster Division:
集群划分:
The cluster is divided into Master and Worker nodes, similar to Hadoop’s Master and Slave nodes.
集群分为 Master 和 Worker 节点,类似于 Hadoop 的 Master 和 Slave 节点。
Master Node
Master 节点
Master Daemon:
Master 守护进程:
Resides on the Master node.
驻留在 Master 节点上。
Manages all Worker nodes.
管理所有 Worker 节点。
Worker Node
Worker 节点
Worker Daemon:
Worker 守护进程:
Resides on Worker nodes.
驻留在 Worker 节点上。
Communicates with the Master node.
与 Master 节点通信。
Manages Executors.
管理执行器 (Executors)。
Driver
驱动程序 (Driver)
Definition:
定义:
The Driver runs the main() function of the application and creating the SparkContext.
Driver 运行应用程序的 main() 函数并创建 SparkContext。
The application is the user-written Spark program, such as WordCount.scala.
应用程序是用户编写的 Spark 程序,例如 WordCount.scala。
Deployment:
部署:
If running on the Master node (e.g., via ./bin/run-example SparkPi 10), SparkPi acts as the Driver on the Master.
如果在 Master 节点上运行(例如,通过 ./bin/run-example SparkPi 10),SparkPi 充当 Master 上的 Driver。
In a YARN cluster, the Driver might run on a Worker node.
在 YARN 集群中,Driver 可能运行在 Worker 节点上。
If running directly on a PC (e.g., using val sc = new SparkContext(“spark://master:7077”, “AppName”)), the Driver runs on the PC. However, this is not recommended due to potential slow communication if the PC and Workers are not on the same local network.
如果在 PC 上直接运行(例如,使用 val sc = new SparkContext(“spark://master:7077”, “AppName”)),Driver 运行在 PC 上。但是,不建议这样做,因为如果 PC 和 Worker 不在同一个局域网内,通信可能会很慢。
Executor
执行器 (Executor)
ExecutorBackend Processes:
ExecutorBackend 进程:
One or more ExecutorBackend processes exist on each Worker.
每个 Worker 上存在一个或多个 ExecutorBackend 进程。
Each process contains an Executor object that holds a thread pool, with each thread capable of executing a task.
每个进程包含一个 Executor 对象,该对象持有一个线程池,每个线程都能够执行一个任务。
In Standalone mode, ExecutorBackend is instantiated as a CoarseGrainedExecutorBackend process.
在独立模式下,ExecutorBackend 被实例化为 CoarseGrainedExecutorBackend 进程。
Each Worker typically runs one CoarseGrainedExecutorBackend process. Multiple processes might be generated when running multiple applications, though this setup might require further experimentation to confirm.
每个 Worker 通常运行一个 CoarseGrainedExecutorBackend 进程。运行多个应用程序时可能会生成多个进程,尽管这种设置可能需要进一步实验来确认。
Application Structure:
应用程序结构:
Each application consists of a Driver and multiple Executors.
每个应用程序由一个 Driver 和多个 Executor 组成。
Tasks running in each Executor belong to the same application.
在每个 Executor 中运行的任务属于同一个应用程序。
Spark Job Execution
Spark 作业执行
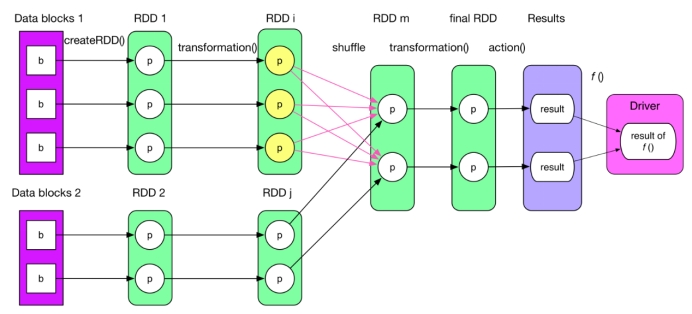
Reading Data and Creating the Initial RDD:
读取数据并创建初始 RDD:
Data Source: The data can come from various sources such as local files, in-memory data structures, HDFS, HBase, etc.
数据源:数据可以来自各种来源,如本地文件、内存数据结构、HDFS、HBase 等。
Creating RDD: The initial RDD is created by reading data from the source using methods like parallelize(), textFile(), or specific data source connectors. For instance, parallelize() is used to create an RDD from an in-memory collection.
创建 RDD:初始 RDD 是通过使用 parallelize()、textFile() 或特定数据源连接器等方法从源读取数据创建的。例如,parallelize() 用于从内存集合创建 RDD。
1 | val sc = new SparkContext(conf) |
2. Transformation Operations on RDD:
2. RDD 上的转换操作:
Transformations: A series of transformation operations are performed on the initial RDD. Each transformation generates a new RDD. Transformations are lazy operations, meaning they are not executed immediately but build up a lineage of RDD transformations.
转换:对初始 RDD 执行一系列转换操作。每个转换生成一个新的 RDD。转换是惰性操作,意味着它们不会立即执行,而是构建 RDD 转换的血统。
Types of Transformations: Examples include map(), filter(), flatMap(), reduceByKey(), etc. Each transformation operation results in a new RDD containing a different type of data (T).
转换类型:示例包括 map()、filter()、flatMap()、reduceByKey() 等。每个转换操作都会产生一个包含不同类型数据 (T) 的新 RDD。
1 | val words = data.flatMap(line => line.split(" ")) |
3. Action Operations on the Final RDD:
3. 最终 RDD 上的动作操作:
Actions: Actions trigger the execution of the transformations. When an action is performed on the final RDD, the entire DAG of transformations is executed.
动作:动作触发转换的执行。当在最终 RDD 上执行动作时,整个转换 DAG 将被执行。
Execution: Each partition of the RDD is computed based on the transformations defined, and the results are combined.
执行:RDD 的每个分区根据定义的转换进行计算,结果被合并。
Types of Actions: Examples include count(), collect(), saveAsTextFile(), etc.
动作类型:示例包括 count()、collect()、saveAsTextFile() 等。
1 | val result = wordCounts.collect() |
4. Returning Results and Final Computation:
4. 返回结果和最终计算:
Result Collection: The result of the action is returned to the driver program. For example, collect() returns the entire dataset to the driver, while count() returns the number of elements.
结果收集:动作的结果返回给驱动程序。例如,collect() 将整个数据集返回给驱动程序,而 count() 返回元素数量。
Final Computation: Any final computations or operations on the collected results can be performed within the driver program. This can include further processing, aggregation, or saving the results to an external storage system.
最终计算:收集结果上的任何最终计算或操作都可以在驱动程序中执行。这可以包括进一步处理、聚合或将结果保存到外部存储系统。
1 | result.foreach(println) |
Caching and Checkpointing
缓存和检查点 (Checkpointing)
Caching: RDDs can be cached to memory to speed up subsequent operations. This is useful when the same RDD is reused multiple times in the workflow.
缓存:RDD 可以缓存到内存中以加速后续操作。当同一个 RDD 在工作流中被多次重用时,这很有用。
Speeds up reuse of rdd. Stored in memory/disk.
加速 RDD 的重用。存储在内存/磁盘中。
RDD reused multiple times.
RDD 被多次重用。
1 | wordCounts.cache() |
Checkpointing: RDDs can be checkpointed to disk for fault tolerance, ensuring that the lineage information is truncated, and the RDD can be recovered from the checkpoint file.
检查点:RDD 可以设置检查点到磁盘以实现容错,确保血统信息被截断,并且 RDD 可以从检查点文件恢复。
Break RDD lineage for fault tolerance 为了容错断开 RDD 血统
1 | sc.setCheckpointDir("hdfs:///checkpoint/") |
Partitioning and Dependencies
分区和依赖
Partitions: The number of partitions in an RDD is not fixed and can be set by the user to control parallelism and resource allocation.
分区:RDD 中的分区数量不是固定的,可以由用户设置以控制并行性和资源分配。
a partition is a basic unit of parallelism. It represents a chunk or slice of data within an RDD (Resilient Distributed Dataset) or DataFrame/Dataset that can be processed in parallel on different nodes in a cluster
分区是并行性的基本单位。它代表 RDD(弹性分布式数据集)或 DataFrame/Dataset 中的数据块或切片,可以在集群中的不同节点上并行处理。
1 | val data = sc.textFile("hdfs:///data/input.txt", numPartitions = 10) |
Dependencies: The dependency relationship between RDDs can be one-to-one (narrow dependencies) or many-to-many (wide dependencies). Narrow dependencies allow for more efficient execution as partitions can be processed independently, while wide dependencies require shuffling data across the network.
依赖关系:RDD 之间的依赖关系可以是一对一(窄依赖)或多对多(宽依赖)。窄依赖允许更高效的执行,因为分区可以独立处理,而宽依赖需要跨网络 Shuffle 数据。
Narrow Dependencies: Each partition of the parent RDD is used by at most one partition of the child RDD.
窄依赖:父 RDD 的每个分区最多被子 RDD 的一个分区使用。
Wide Dependencies: Multiple child partitions depend on multiple parent partitions, requiring data shuffling.
宽依赖:多个子分区依赖于多个父分区,需要数据 Shuffle。
Dependency Types
依赖类型
1. ShuffleDependency:
1. ShuffleDependency(宽依赖):
Wide Dependency: Each partition of the parent RDD can be used by multiple child partitions, requiring a shuffle of data across the network.
宽依赖:父 RDD 的每个分区可以被多个子分区使用,需要跨网络 Shuffle 数据。
Causes the job to be split into multiple stages.
导致作业被拆分为多个阶段。
The presence of a ShuffleDependency triggers the creation of a new stage.
ShuffleDependency 的存在触发了新阶段的创建。
2. NarrowDependency:
2. NarrowDependency(窄依赖):
Narrow Dependency: Each partition of the parent RDD is used by at most one partition of the child RDD.
窄依赖:父 RDD 的每个分区最多被子 RDD 的一个分区使用。
Operations like map, filter, and union create narrow dependencies.
像 map、filter 和 union 这样的操作会创建窄依赖。
These dependencies do not cause stage boundaries and are included in the same stage.
这些依赖关系不会导致阶段边界,并且包含在同一个阶段中。
Spark Job Submission Implementation Details
Spark 作业提交实现细节
When an action is called on an RDD, it triggers a series of steps that Spark follows to submit and execute a job. Here’s a detailed explanation of the job submission process:
当在 RDD 上调用动作时,它会触发 Spark 提交和执行作业的一系列步骤。以下是作业提交过程的详细解释:
1. Action Call and Job Creation:
1. 动作调用和作业创建:
When rdd.action() is called, it triggers the DAGScheduler.runJob(rdd, processPartition, resultHandler) method.
当调用 rdd.action() 时,它会触发 DAGScheduler.runJob(rdd, processPartition, resultHandler) 方法。
This method initiates the creation of a job.
此方法启动作业的创建。
2. Partition Information and Result Array:
2. 分区信息和结果数组:
runJob() retrieves the number and type of partitions that should exist in finalRDD by calling rdd.getPartitions(). This returns an array of Partition objects.
runJob() 通过调用 rdd.getPartitions() 检索 finalRDD 中应存在的分区数量和类型。这返回一个 Partition 对象数组。
Based on the number of partitions, a new array Result[Result](partitions.size) is created to hold the results.
根据分区数量,创建一个新数组 Result[Result](partitions.size) 来保存结果。
3. Job Submission:
3. 作业提交:
runJob calls DAGScheduler.runJob(rdd, cleanedFunc, partitions, allowLocal, resultHandler).
runJob 调用 DAGScheduler.runJob(rdd, cleanedFunc, partitions, allowLocal, resultHandler)。
cleanedFunc is the result of processPartition after closure cleanup to ensure it can be serialized and passed to tasks on different nodes.
cleanedFunc 是闭包清理后的 processPartition 的结果,以确保它可以序列化并传递给不同节点上的任务。
4. Submit Job:
4. 提交作业:
runJob in DAGScheduler continues to call submitJob(rdd, func, partitions, allowLocal, resultHandler) to submit the job.
DAGScheduler 中的 runJob 继续调用 submitJob(rdd, func, partitions, allowLocal, resultHandler) 来提交作业。
submitJob() first generates a jobId.
submitJob() 首先生成一个 jobId。
The function func is wrapped again, and a JobSubmitted message is sent to DAGSchedulerEventProcessActor.
函数 func 再次被包装,并且 JobSubmitted 消息被发送到 DAGSchedulerEventProcessActor。
5. Event Handling:
5. 事件处理:
DAGSchedulerEventProcessActor receives the JobSubmitted message.
DAGSchedulerEventProcessActor 接收 JobSubmitted 消息。
The actor then calls dagScheduler.handleJobSubmitted() to process the submitted job, adhering to the event-driven model.
然后 actor 调用 dagScheduler.handleJobSubmitted() 来处理提交的作业,遵循事件驱动模型。
6. Stage Creation and Submission:
6. 阶段创建和提交:
handleJobSubmitted() calls newStage() to create the final stage.
handleJobSubmitted() 调用 newStage() 来创建最终阶段。
It then calls submitStage(finalStage).
然后它调用 submitStage(finalStage)。
Since finalStage may have parent stages, these parent stages are submitted first.
由于 finalStage 可能有父阶段,这些父阶段会先提交。
Once the parent stages are completed, finalStage is submitted again for execution.
一旦父阶段完成,finalStage 将再次提交执行。
This process of resubmission is managed by handleJobSubmitted() and ultimately handled by submitWaitingStages().
这种重新提交的过程由 handleJobSubmitted() 管理,并最终由 submitWaitingStages() 处理。
Spark Shuffle Principle
Spark Shuffle 原理
The shuffle describes the process of transferring data from the map stage (or upstream tasks) to the reduce stage (or downstream tasks).
Shuffle 描述了将数据从 Map 阶段(或上游任务)传输到 Reduce 阶段(或下游任务)的过程。
Shuffle is the bridge between Map and Reduce phase. Map output must go through the link of shuffle to be used in Reduce.
Shuffle 是 Map 和 Reduce 阶段之间的桥梁。Map 输出必须通过 Shuffle 链路才能在 Reduce 中使用。
Spark shuffle is a mechanism in Apache Spark that redistributes data across different partitions to perform operations that require grouping or re-partitioning the data. It’s an essential part of distributed data processing in Spark but is often associated with significant performance overhead due to the movement of data between nodes in a cluster.
Spark shuffle 是 Apache Spark 中的一种机制,它在不同分区之间重新分配数据,以执行需要分组或重新分区数据的操作。它是 Spark 分布式数据处理的重要组成部分,但由于数据在集群节点之间的移动,通常伴随着显著的性能开销。
A shuffle occurs when Spark needs to reorganize data across the nodes of a cluster. This happens when transformations like the following are used:
当 Spark 需要在集群节点之间重组数据时,就会发生 Shuffle。当使用如下转换时会发生这种情况:
groupByKey, reduceByKey, aggregateByKey, join, repartition:
Shuffle Expensive?
为什么 Shuffle 很昂贵?
The shuffle operation can be costly in terms of both time and resources due to the following reasons:
由于以下原因,Shuffle 操作在时间和资源方面可能都很昂贵:
1. Data Movement:
数据移动:
During a shuffle, data is moved across different nodes in the cluster, which involves network communication. Network IO is much slower than reading or writing from local memory or disk.
在 Shuffle 过程中,数据在集群的不同节点之间移动,这涉及网络通信。网络 IO 比从本地内存或磁盘读取或写入要慢得多。
2. Disk I/O:
磁盘 I/O:
To handle large amounts of data during the shuffle, Spark often writes intermediate data to disk. This occurs when the data being shuffled cannot fit into memory.
为了在 Shuffle 期间处理大量数据,Spark 经常将中间数据写入磁盘。这发生在被 Shuffle 的数据无法放入内存时。
3. Serialization and Deserialization:
3. 序列化和反序列化:
Data that is transferred over the network is serialized, which means converting it into a format suitable for network transfer. On the receiving end, the data must be deserialized back into the original format. This process can add to the overhead.
通过网络传输的数据被序列化,这意味着将其转换为适合网络传输的格式。在接收端,数据必须反序列化回原始格式。这个过程会增加开销。
4. Sorting and Aggregation:
4. 排序和聚合:
For operations like groupByKey or reduceByKey, data needs to be sorted and aggregated after it has been shuffled, which can further add to the time taken.
对于像 groupByKey 或 reduceByKey 这样的操作,数据在 Shuffle 后需要进行排序和聚合,这可能会进一步增加所需的时间。
The SortShuffleManager is the default shuffle manager in Apache Spark, designed to optimize the process of data shuffling, which is the redistribution of data across partitions between stages. It is a key part of how Spark handles data movement during operations like reduceByKey, join, or any operation that requires reshuffling data.
SortShuffleManager 是 Apache Spark 中的默认 Shuffle 管理器,旨在优化数据 Shuffle 过程,即阶段之间跨分区的数据重新分配。它是 Spark 处理 reduceByKey、join 或任何需要重新 Shuffle 数据的操作期间数据移动的关键部分。
The SortShuffleManager in Spark has two main operation mechanisms:
Spark 中的 SortShuffleManager 有两种主要的操作机制:
Ordinary Operation Mechanism:
普通运行机制:
This is the standard way SortShuffleManager works.
这是 SortShuffleManager 工作的标准方式。
It sorts the data by key before writing it to disk during a shuffle. This helps improve efficiency when tasks need to access the data later, as it minimizes the number of files and optimizes read performance.
它在 Shuffle 期间将数据写入磁盘之前按键对数据进行排序。这有助于提高任务稍后访问数据时的效率,因为它最大限度地减少了文件数量并优化了读取性能。
It organizes the data by key before saving it. Think of it like sorting your files into folders before putting them in a box. This makes it easier to find what you need later.
它在保存数据之前按键组织数据。可以将其想象为在将文件放入盒子之前将其分类到文件夹中。这使得稍后更容易找到所需的内容。
Because the data is sorted, it takes less time to read it when you need to use it again.
因为数据是排序的,所以当你需要再次使用它时,读取它的时间更少。
Bypass Operation Mechanism:
旁路运行机制 (Bypass Operation Mechanism):
This mechanism is used when the number of partitions is below a certain threshold (default is 200).
当分区数量低于特定阈值(默认为 200)时,使用此机制。
Instead of sorting the data, it directly writes the data to disk using a hash-based approach. This reduces overhead for smaller datasets, making the process quicker when sorting isn’t necessary.
它不排序数据,而是使用基于哈希的方法直接将数据写入磁盘。这减少了较小数据集的开销,使得在不需要排序时过程更快。
Instead of sorting the data, it just puts it directly into files without organizing it first. It’s like throwing your files into a box without sorting them if you don’t have too many. This saves time and effort.
它不是对数据进行排序,而是直接将其放入文件中,而不先进行组织。就像如果你没有太多文件,就把它们扔进盒子里而不进行分类一样。这节省了时间和精力。