Chapter 2
第2章
Spark runs in a variety of modes and can be run in either local mode or pseudo-distributed mode on a stand-alone machine. When running in a Cluster mode in a distributed setup, the underlying resource scheduling can either use Mesos or Yarn, or Spark’s Standalone mode itself. Before each pattern, introduce some basic concepts and models.
Spark 可以在多种模式下运行,既可以在单机上以本地模式或伪分布式模式运行。当在分布式设置中以集群模式运行时,底层的资源调度可以使用 Mesos 或 Yarn,也可以使用 Spark 自带的 Standalone 模式。在介绍每种模式之前,先介绍一些基本概念和模型。
- Application similar to Hadoop Map Reduce, is a user-written Spark Application that contains code for a Driver function and Executor code that runs across multiple nodes in a cluster.
- Application 类似于 Hadoop Map Reduce,是一个用户编写的 Spark 应用程序,其中包含 Driver 函数的代码以及在集群中多个节点上运行的 Executor 代码。
- Driver: The Driver in Spark runs Application’s main() function and creates Spark Context, which is created to prepare the running environment for the Spark Application.
- Driver:Spark 中的 Driver 运行应用程序的 main() 函数并创建 Spark Context,Spark Context 的创建是为了给 Spark 应用程序准备运行环境。
- Executor: An application runs a process on the Worker node that is responsible for running certain tasks and storing the data in memory or on disk.
- Executor:应用程序在 Worker 节点上运行的一个进程,负责运行特定任务并将数据存储在内存或磁盘上。
- Cluster Manager: Refers to external services that obtain resources on the cluster。
- Cluster Manager:指在集群上获取资源的外部服务。
- Worker: Any node in the cluster that can run the Application code.
- Worker:集群中任何可以运行应用程序代码的节点。
- Task: the unit of work that is sent to an Executor is the basic unit that runs the Application.
- Task:发送给 Executor 的工作单元,是运行应用程序的基本单元。
- Job: Parallel computing, consisting of multiple tasks, is triggered by Spark Action.
- Job:包含多个任务的并行计算,由 Spark Action 触发。
- Stage: Each Job is split into groups of tasks as a Task Set.
- Stage:每个 Job 被拆分成多组任务,作为一个 Task Set(任务集)。
- RDD: Spark’s basic cell, which can be operated on through a series of operators.
- RDD:Spark 的基本单元,可以通过一系列算子进行操作。
- Shared variables: When the Spark Application runs, you may need to share some variables for use by Task or Driver.
- Shared variables(共享变量):当 Spark 应用程序运行时,你可能需要共享一些变量供 Task 或 Driver 使用。
- Shuffle Dependency: or Shuffle Dependency, which requires that you the data of all parent RDD partitions and then run Shuffle between nodes.
- Shuffle Dependency(宽依赖):或称 Shuffle 依赖,它要求你计算所有父 RDD 分区的数据,然后在节点之间运行 Shuffle。
- Narrow dependencies: Or Narrow Dependency, refers to a specific RDD.
- Narrow dependencies(窄依赖):或称 Narrow Dependency,指的是特定的 RDD 依赖关系。
- DAG Scheduler: Builds a stage-based DAG based on Job and submits stages to the Task Scheduler.
- DAG Scheduler:基于 Job 构建基于 Stage 的 DAG(有向无环图),并将 Stage 提交给 Task Scheduler。
- Task Scheduler: The Task Set is submitted to the Worker to run, where each Executor runs tasks.
- Task Scheduler:将 Task Set 提交给 Worker 运行,其中每个 Executor 负责运行任务。
Cluster Manager
集群管理器 (Cluster Manager)
In Apache Spark, the cluster manager is a crucial component that manages resources (such as CPU and memory) across a distributed cluster of machines. It is responsible for allocating resources to Spark jobs, launching executors on worker nodes, and ensuring that jobs run efficiently across the cluster. Essentially, the cluster manager handles the coordination and scheduling of tasks that make up a Spark application.
在 Apache Spark 中,cluster manager(集群管理器)是一个关键组件,用于管理分布式机器集群中的资源(如 CPU 和内存)。它负责为 Spark 作业分配资源,在 Worker 节点上启动 Executor,并确保作业在集群中高效运行。本质上,集群管理器处理构成 Spark 应用程序的任务的协调和调度。
Key Functions of a Cluster Manager in Spark:
Spark 中 Cluster Manager 的主要功能:
- Resource Allocation: The cluster manager allocates resources (e.g., CPU, memory) across the cluster to Spark applications based on their requirements. It ensures that resources are distributed effectively and that no node is over- or under-utilized.
- 资源分配 (Resource Allocation):集群管理器根据 Spark 应用程序的需求,将集群中的资源(例如 CPU、内存)分配给它们。它确保资源被有效分配,并且没有节点过载或利用率不足。
- Task Scheduling: The cluster manager schedules tasks (individual units of work) on the available worker nodes. It decides where to run each task, ensuring optimal use of cluster resources.
- 任务调度 (Task Scheduling):集群管理器在可用的 Worker 节点上调度任务(独立的工作单元)。它决定在何处运行每个任务,确保集群资源的最佳利用。
- Fault Tolerance: If a task or executor fails, the cluster manager is responsible for restarting it on another node to ensure that the Spark application continues running.
- 容错性 (Fault Tolerance):如果任务或 Executor 失败,集群管理器负责在另一个节点上重启它,以确保 Spark 应用程序继续运行。
- Executor Management: The cluster manager launches executors, which are JVM processes that run tasks on worker nodes. It also manages the lifecycle of these executors, ensuring they are terminated when no longer needed.
- Executor 管理 (Executor Management):集群管理器启动 Executor,这是在 Worker 节点上运行任务的 JVM 进程。它还管理这些 Executor 的生命周期,确保它们在不再需要时被终止。
- Communication: The cluster manager facilitates communication between the Spark driver (which coordinates the execution of the job) and the worker nodes where executors run.
- 通信 (Communication):集群管理器促进 Spark Driver(协调作业执行)与运行 Executor 的 Worker 节点之间的通信。
Spark Deployment mode
Spark 部署模式
Apache Spark supports multiple deployment modes, which define how Spark applications are executed across a cluster. These modes determine where the Spark driver runs and how resources are allocated.
Apache Spark 支持多种部署模式,这些模式定义了 Spark 应用程序如何在集群中执行。这些模式决定了 Spark Driver 在哪里运行以及资源如何分配。
We have 4 types of deployment mode which categorized in 2 modes.
我们有 4 种类型的部署模式,归类为 2 种大模式。
- Local mode
- 本地模式 (Local mode)
- Standalone mode
- 独立模式 (Standalone mode)
- Yarn Mode
- Yarn 模式
- Mesos Mode
- Mesos 模式
Local Mode
本地模式 (Local Mode)
Description: In Local mode, Spark runs on a single machine, with the driver and executors all running on the same node. This mode is useful for development, testing, and debugging Spark applications.
描述:在本地模式下,Spark 运行在单台机器上,Driver 和 Executor 都运行在同一个节点上。这种模式对于开发、测试和调试 Spark 应用程序非常有用。
Execution: You can specify the number of threads to use.
执行:你可以指定要使用的线程数。
Use Case: Small datasets, development, and debugging.
用例:小数据集、开发和调试。
Command:
命令:
- To start shell:
spark-shell(scala) - 启动 shell:
spark-shell(scala) - To start python shell:
pyspark - 启动 python shell:
pyspark - To start spark sql:
sparksql - 启动 spark sql:
sparksql - To close shell:
:quit - 关闭 shell:
:quit - Spark job Web UI:
ipaddress:4040(niit:4040) - Spark 作业 Web UI:
ipaddress:4040(niit:4040)
Standalone Mode
独立模式 (Standalone Mode)
Spark Standalone refers to a simple cluster manager that comes built into Apache Spark. It allows you to run Spark applications on a cluster without requiring an external cluster manager like Hadoop YARN or Apache Mesos. This setup is ideal for small to medium-scale deployments where you don’t need the complexity of more sophisticated resource management systems.
Spark Standalone 指的是 Apache Spark 内置的一个简单的集群管理器。它允许你在集群上运行 Spark 应用程序,而无需像 Hadoop YARN 或 Apache Mesos 这样的外部集群管理器。这种设置非常适合中小型部署,因为你不需要复杂的高级资源管理系统。
Description: Standalone mode is Spark’s built-in cluster manager. In this mode, you can deploy a Spark cluster by starting a master node and multiple worker nodes. The Spark driver can run on any node in the cluster or outside the cluster.
描述:Standalone 模式是 Spark 的内置集群管理器。在这种模式下,你可以通过启动一个 Master 节点和多个 Worker 节点来部署 Spark 集群。Spark Driver 可以运行在集群中的任何节点上,也可以运行在集群外部。
The Master is the cluster manager in Spark’s Standalone mode, responsible for managing and allocating resources across the cluster to various Spark applications.
Master 是 Spark Standalone 模式下的 cluster manager,负责管理和分配集群资源给各种 Spark 应用程序。
Execution: You manually manage the cluster nodes, and Spark manages resource allocation across the workers.
执行:你手动管理集群节点,Spark 管理 Worker 之间的资源分配。
Use Case: Dedicated Spark clusters where Spark is the primary workload.
用例:Spark 作为主要工作负载的专用 Spark 集群。
Spark standalone cluster running on two nodes with two workers.
运行在两个节点上的带有两个 Worker 的 Spark Standalone 集群。
- A client process submits an application to the master.
- 客户端进程向 Master 提交应用程序。
- The master instructs one of its workers to launch a driver.
- Master 指示其 Worker 之一启动 Driver。
- The worker spawns a driver JVM.
- 该 Worker 启动一个 Driver JVM。
- The master instructs both workers to launch executors for the application.
- Master 指示两个 Worker 为该应用程序启动 Executor。
- The workers spawn executor JVMs.
- Worker 启动 Executor JVM。
- The driver and executors communicate independent of the cluster’s processes.
- Driver 和 Executor 独立于集群进程进行通信。
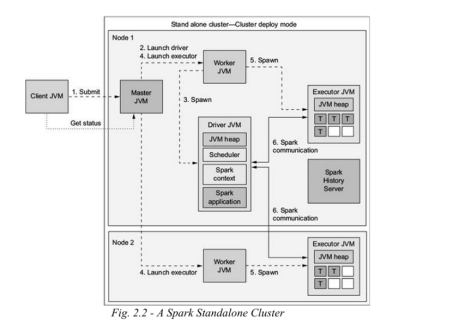
In the Details:
详细说明:
1. A client process submits an application to the master:
1. 客户端进程向 Master 提交应用程序:
The client submits the application using the spark-submit command or an interactive shell (e.g., spark-shell or API).
客户端使用 spark-submit 命令或交互式 Shell(例如 spark-shell 或 API)提交应用程序。
2. The master instructs one of its workers to launch a driver:
2. Master 指示其 Worker 之一启动 Driver:
The master node receives the submission and schedules a worker node to launch the driver process.
Master 节点接收提交,并调度一个 Worker 节点来启动 Driver 进程。
The driver is responsible for orchestrating the execution of the Spark application, managing the application logic, distributing tasks, and collecting results.
Driver 负责编排 Spark 应用程序的执行,管理应用程序逻辑,分发任务并收集结果。
The master selects the worker node based on available resources (CPU cores, memory, etc.).
Master 根据可用资源(CPU 核心、内存等)选择 Worker 节点。
3. The worker spawns a driver JVM:
3. Worker 启动一个 Driver JVM:
The selected worker node starts a new JVM (Java Virtual Machine) instance that runs the driver for the submitted application.
被选中的 Worker 节点启动一个新的 JVM(Java 虚拟机)实例,该实例运行已提交应用程序的 Driver。
The driver JVM creates a SparkContext or SparkSession, which acts as the entry point for interacting with the cluster.
Driver JVM 创建 SparkContext 或 SparkSession,作为与集群交互的入口点。
The driver establishes a direct communication link with the master node to request resources and submit tasks.
Driver 与 Master 节点建立直接通信链路,以请求资源并提交任务。
4. The master instructs both workers to launch executors for the application:
4. Master 指示两个 Worker 为该应用程序启动 Executor:
The driver requests resources (CPU cores and memory) from the master to execute tasks.
Driver 向 Master 请求资源(CPU 核心和内存)以执行任务。
The master allocates resources across the available worker nodes and instructs them to start executors.
Master 在可用的 Worker 节点之间分配资源,并指示它们启动 Executor。
Executors are processes launched on the worker nodes that execute tasks, perform computations, and store data for the duration of the application.
Executors 是在 Worker 节点上启动的进程,它们在应用程序运行期间执行任务、进行计算并存储数据。
5. The workers spawn executor JVMs:
5. Worker 启动 Executor JVM:
Both worker nodes start executor JVM processes according to the resources allocated by the master.
两个 Worker 节点根据 Master 分配的资源启动 Executor JVM 进程。
Each executor is responsible for running the tasks that the driver assigns. Executors can also cache data and handle shuffle operations (when data needs to be exchanged between partitions).
每个 Executor 负责运行 Driver 分配的任务。Executor 还可以缓存数据并处理 Shuffle 操作(当需要在分区之间交换数据时)。
Executors perform their work independently and periodically send results back to the driver.
Executor 独立执行工作,并定期将结果发送回 Driver。
6. The driver and executors communicate independently of the cluster’s processes:
6. Driver 和 Executor 独立于集群进程进行通信:
Once the executors are running, they communicate directly with the driver without needing to involve the master.
一旦 Executor 运行起来,它们将直接与 Driver 通信,而无需 Master 参与。
The driver coordinates task execution, sending tasks to executors and collecting results once the tasks are completed.
Driver 协调任务执行,将任务发送给 Executor,并在任务完成后收集结果。
Executors report progress, and task statuses (e.g., success or failure) are sent back to the driver.
Executor 报告进度,任务状态(例如成功或失败)被发送回 Driver。
The master node is only involved in the resource allocation process; it does not participate in the task execution or coordination. Master 节点仅参与资源分配过程;它不参与任务执行或协调。
Commands:
命令:
To start master and worker
启动 Master 和 Worker
Open spark directory:
cd $SPARK_HOME打开 spark 目录:
cd $SPARK_HOMETo start master and worker:
sbin/start-all.sh启动 Master 和 Worker:
sbin/start-all.shMaster UI:
ipaddress:8080(niit01:8080)Master UI:
ipaddress:8080(niit01:8080)
Spark Standalone Process Analysis
Spark Standalone 流程分析
Spark Standalone Process Analysis The nodes involved in Spark Standalone mainly include Master node, Worker node and client node. Involved in the process are mainly process the Client, Client submitted for the Master, the Worker, GoarseGrainedExecutorBackend.
Spark Standalone 流程分析:Spark Standalone 涉及的节点主要包括 Master 节点、Worker 节点和 Client 节点。涉及的进程主要有 Client、提交给 Master 的 Client、Worker、CoarseGrainedExecutorBackend(粗粒度执行器后端)。
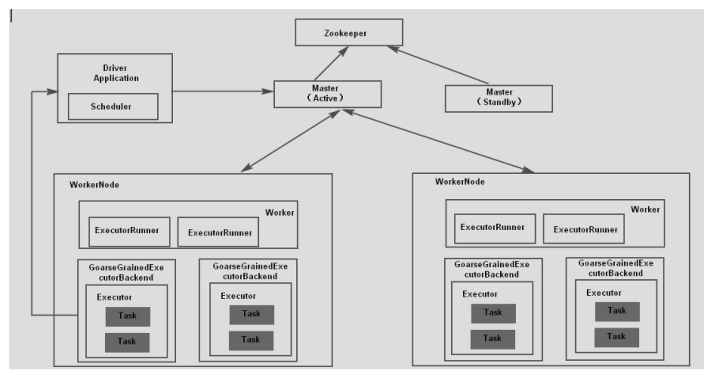
The specific steps for Spark Application submission are as follows:
Spark 应用程序提交的具体步骤如下:
- After the Spark cluster starts, the worker node will have a heartbeat mechanism to keep communication with the master;
- Spark 集群启动后,Worker 节点将通过心跳机制保持与 Master 的通信;
- Spark Context will apply to the Master for resources after connecting to the master, and the Master will allocate the worker’s resources according to the worker’s heartbeat and start the Executor process of the Worker;
- Spark Context 连接到 Master 后会向其申请资源,Master 根据 Worker 的心跳分配 Worker 资源,并启动 Worker 的 Executor 进程;
- Spark Context parses the program code into DAG structure and submits to Dag Scheduler;
- Spark Context 将程序代码解析为 DAG 结构并提交给 DAG Scheduler;
- DAG is divided into many stages in the Dag Scheduler, and each stage contains multiple tasks;
- DAG 在 DAG Scheduler 中被划分为许多 Stage,每个 Stage 包含多个 Task;
- The stage will be submitted to the Task Scheduler, and the Task Scheduler will assign the task to the worker and submit it to the Executor process, which will create a thread pool to execute the task and report the execution to Spark Context until the task is completed;
- Stage 将被提交给 Task Scheduler,Task Scheduler 将任务分配给 Worker 并提交给 Executor 进程,Executor 进程将创建一个线程池来执行任务,并向 Spark Context 报告执行情况,直到任务完成;
- After all tasks are completed, Spark Context logs out to Master and releases resources;
- 所有任务完成后,Spark Context 向 Master 注销并释放资源;
Click Me to See how Standalone Mode works
YARN Mode
YARN 模式
Description: YARN (Yet Another Resource Negotiator) is the resource manager used by Hadoop. In YARN mode, Spark applications are executed on a Hadoop cluster, leveraging YARN to allocate resources.
描述:YARN (Yet Another Resource Negotiator) 是 Hadoop 使用的资源管理器。在 YARN 模式下,Spark 应用程序在 Hadoop 集群上执行,利用 YARN 分配资源。
In YARN , the master functionality is provided by the respective cluster managers (ResourceManager in YARN) referring to YARN’s role as a resource manager for Spark application.
在 YARN 中,Master 功能由各自的集群管理器(YARN 中的 ResourceManager)提供,指的是 YARN 作为 Spark 应用程序的资源管理器的角色。
The concept of a “master” in Spark refers to the Driver process.
Spark 中 “master” 的概念指的是 Driver 进程。
In YARN cluster mode, the Driver runs inside the YARN cluster on one of the nodes chosen by YARN.
在 YARN cluster 模式下,Driver 运行在 YARN 集群内部,位于 YARN 选择的其中一个节点上。
Execution: Spark can run in two sub-modes on YARN: client mode and cluster mode.
执行:Spark 可以在 YARN 上以两种子模式运行:client(客户端)模式和 cluster(集群)模式。
- Client Mode: The Spark driver runs on the client machine (e.g., where you submit the job), and the executors run on the YARN cluster.
- Client Mode:Spark Driver 运行在客户端机器上(例如,你提交作业的地方),而 Executor 运行在 YARN 集群上。
- Cluster Mode: The Spark driver runs inside the YARN cluster, on one of the worker nodes.
- Cluster Mode:Spark Driver 运行在 YARN 集群内部的某个 Worker 节点上。
Use Case: Hadoop clusters where Spark needs to coexist with other Hadoop applications (e.g., MapReduce, HBase).
用例:Spark 需要与其他 Hadoop 应用程序(例如 MapReduce、HBase)共存的 Hadoop 集群。
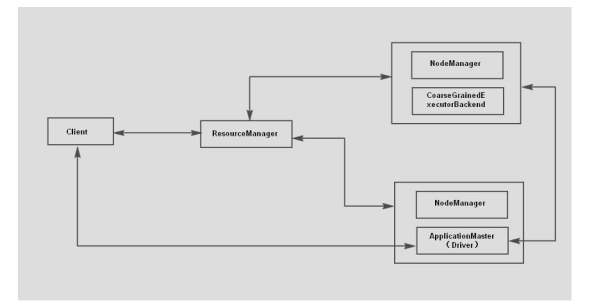
Yarn-Cluster Process Analysis
Yarn-Cluster 流程分析
- The client submits a Spark Application to the YARN.
- 客户端向 YARN 提交 Spark 应用程序。
- After the request is received, Once YARN receives the job request, it assigns a container to run the ApplicationMaster. The ApplicationMaster then launches the Driver program inside the cluster. The Driver is responsible for initializing the SparkContext, which is the entry point for interacting with Spark and the cluster.
- 收到请求后,一旦 YARN 接收到作业请求,它会分配一个 container(容器)来运行 ApplicationMaster。ApplicationMaster 随后在集群内部启动 Driver 程序。Driver 负责初始化 SparkContext,这是与 Spark 和集群交互的入口点。
- Application Master requests resources from Resource Manager to run Executor. Application Master requests and assigns resources through the Yarn Allocation Handle.
- Application Master 向 Resource Manager 请求资源以运行 Executor。Application Master 通过 Yarn Allocation Handle 请求并分配资源。
- Resource Manager assigns containers to Application Master, The ApplicationMaster communicates with the NodeManagers on the allocated nodes to launch the Coarse-Grained Executors. While a Coarse Grained Assembly starts, you start registering with the Spark Context in the Application Master and applying for a Task, just as you would do in the Standalone mode. It’s just that Spark Context was initialized in Spark Application with the Older-Grained Scheduler Backend for task scheduling with the Yarn Cluster Scheduler, while the Yarn Cluster Scheduler is just a simple wrapper to the Task Schedulelmpl, adding wait logic to the Executor, and so on.
- Resource Manager 将容器分配给 Application Master,ApplicationMaster 与已分配节点上的 NodeManagers 通信以启动 Coarse-Grained Executors(粗粒度执行器)。当粗粒度组件启动时,它开始向 Application Master 中的 Spark Context 注册并申请 Task,就像在 Standalone 模式下一样。只是 Spark Context 是在 Spark 应用程序中使用 Coarse-Grained Scheduler Backend 初始化的,用于与 Yarn Cluster Scheduler 进行任务调度,而 Yarn Cluster Scheduler 只是 Task SchedulerImpl 的一个简单封装,增加了对 Executor 的等待逻辑等。
- Application Master Spark Context in distribution of Task to Coarse-Grained Executor Backend execution, Coarse Grained Executor Backend Operation Task and to Spark the Context report operation condition.
- Application Master 中的 Spark Context 将 Task 分发给 Coarse-Grained Executor Backend 执行,Coarse Grained Executor Backend 运行 Task 并向 Spark Context 报告运行情况。
The term “coarse-grained” is used because, in Spark, executors are long-running processes that handle multiple tasks over their lifetime. Rather than creating a new executor for each task (which would be a fine-grained approach), a coarse-grained approach keeps executors alive for the entire duration of the job, allowing them to handle many tasks. This reduces the overhead of creating and destroying executors frequently and leads to better resource utilization.
术语“粗粒度 (coarse-grained)”之所以被使用,是因为在 Spark 中,Executor 是长生命周期的进程,在其生命周期内处理多个任务。与其为每个任务创建一个新的 Executor(这将是一种细粒度的方法),粗粒度方法在整个作业持续期间保持 Executor 存活,允许它们处理许多任务。这减少了频繁创建和销毁 Executor 的开销,并带来了更好的资源利用率。
Mesos Mode
Mesos 模式
What is Mesos?
什么是 Mesos?
Apache Mesos is an open-source cluster management and resource scheduling platform that provides efficient resource isolation and sharing across distributed applications or frameworks. Essentially, Mesos acts as a resource manager, allowing multiple distributed applications (like Apache Spark, Hadoop, Kubernetes, and others) to share the same cluster of machines efficiently. It abstracts the underlying hardware resources (CPU, memory, disk, etc.) and allows applications to run in a highly scalable, fault-tolerant, and distributed manner.
Apache Mesos 是一个开源的集群管理和资源调度平台,它为分布式应用程序或框架提供高效的资源隔离和共享。本质上,Mesos 充当资源管理器的角色,允许多个分布式应用程序(如 Apache Spark、Hadoop、Kubernetes 等)高效地共享同一个机器集群。它抽象了底层硬件资源(CPU、内存、磁盘等),并允许应用程序以高度可扩展、容错和分布式的方式运行。
Description: Mesos is a cluster manager that can run various distributed applications, including Spark. In Mesos mode, Spark applications share cluster resources with other frameworks managed by Mesos.
描述:Mesos 是一个可以运行各种分布式应用程序(包括 Spark)的集群管理器。在 Mesos 模式下,Spark 应用程序与 Mesos 管理的其他框架共享集群资源。
Execution: Similar to YARN, Mesos can run Spark in client or cluster mode.
执行:与 YARN 类似,Mesos 可以以 client(客户端)或 cluster(集群)模式运行 Spark。
Client Mode: The driver runs on the client machine, and the executors run on Mesos-managed nodes.
Client Mode:Driver 运行在客户端机器上,Executor 运行在 Mesos 管理的节点上。
Cluster Mode: The driver runs inside the Mesos cluster on one of the worker nodes.
Cluster Mode:Driver 运行在 Mesos 集群内部的某个 Worker 节点上。
Use Case: Environments where multiple distributed systems need to share resources, and Mesos is the chosen cluster manager. 用例:多个分布式系统需要共享资源,并且选择 Mesos 作为集群管理器的环境。
Coarse-Grained Mode workflow
粗粒度模式工作流程
- Mesos Master launches executor processes on Mesos Slaves (agents).
- Mesos Master 在 Mesos Slaves (agents) 上启动 Executor 进程。
- Each executor is allocated a fixed amount of cores and memory at startup.
- 每个 Executor 在启动时被分配固定数量的核心和内存。
- These executors stay alive for the entire duration of the Spark job.
- 这些 Executor 在整个 Spark 作业期间保持存活。
- The Driver sends multiple tasks (from different stages) to executors.
- Driver 将多个任务(来自不同的 Stage)发送给 Executor。
- Executors execute tasks one after another → if no task is currently assigned, the executor remains idle (but still consumes reserved resources).
- Executor 一个接一个地执行任务 → 如果当前没有分配任务,Executor 保持空闲(但仍消耗预留资源)。
- Once all tasks are completed and the job finishes, executors shut down, and resources are released.
- 一旦所有任务完成且作业结束,Executor 关闭,资源被释放。
Click Me to See how Coarse-Grained Mode works
Fine-Grained Mode
细粒度模式 (Fine-Grained Mode)
- Mesos Master offers resources from Mesos Slaves to the Spark Driver in very small chunks (per-task level).
- Mesos Master 以非常小的块(任务级别)向 Spark Driver 提供来自 Mesos Slaves 的资源。
- The Driver requests resources for each individual task, instead of holding fixed executors.
- Driver 为每个单独的任务请求资源,而不是持有固定的 Executor。
- Mesos launches tasks directly inside short-lived executor containers on Mesos Slaves.
- Mesos 直接在 Mesos Slaves 上短暂的 Executor 容器内启动任务。
- Each container may run only one or a few tasks, and after finishing them, it immediately releases resources back to Mesos.
- 每个容器可能只运行一个或几个任务,完成它们后,它立即将资源释放回 Mesos。
- If new tasks need to run, the Driver must request fresh resources from Mesos again, and Mesos launches new containers.
- 如果需要运行新任务,Driver 必须再次从 Mesos 请求新资源,并且 Mesos 启动新容器。
- This allows multiple frameworks (e.g., Spark, Hadoop, Kafka) to share cluster resources dynamically, since resources are freed as soon as a task completes.
- 这允许多个框架(例如 Spark、Hadoop、Kafka)动态共享集群资源,因为资源在任务完成后立即被释放。
- Once all tasks are finished, the Spark application ends, and no containers remain.
- 一旦所有任务完成,Spark 应用程序结束,并且没有容器保留。