内存的基础知识
什么是内存,有何作用
- 存储单元、内存地址的概念和联系
- 内存地址从0开始,每个地址对应一个存储单元
- 按字节编址vs按字编址
- 按字节编址:每个存储单元大小为==1字节==,即1B
- 按字编址:每个存储单元大小为1个字。如果字长为16,则每个字的大小为16个二进制位
- 存储单元、内存地址的概念和联系
进程运行的基本原理
指令的工作原理
- 操作码+若干参数(可能包含地址参数)
逻辑地址(相对地址)vs 物理地址(绝对地址)
- 逻辑地址:程序经过编译、链接后生成的指令中指明的是逻辑地址
- 物理地址:实际存放地址
从写程序到程序运行
编辑源代码文件
编译:由源代码文件生成目标模块(高级语言“翻译”为机器语言)
链接:由目标模块生成装入模块,链接后形成完整的逻辑地址
装入:将装入模块装入内存,装入后形成物理地址
即:$源代码文件\stackrel{编译}{\Longrightarrow} 目标模块\stackrel{链接}{\Longrightarrow}装入模块\stackrel{装入}{\Longrightarrow} 物理地址$
一个具体的🌰
- 编写一段程序并保存为
hello.c
1
2
3
4
5
int main() {
printf("看好了世界,我这就让你崩溃\n");
return 0;
}- 编译:执行语句:
gcc hello.c -o hello.o,高级语言翻译成机器能看懂的二进制目标文件hello.o。此时生成的.o文件就像乐高零件:有main函数机器码,但printf函数的位置还标记着”待填充”(就像网购时写的”地址不详”) - 链接:执行语句:
gcc hello.o -o hello,把C标准库里的printf函数实现(在libc.so里)和你的目标文件拼在一起,生成可执行文件hello。此时程序有了完整的逻辑地址,比如printf被分配了假地址0x401000(就像你网购时写的”小区快递柜”这种模糊地址) - 装入:加载器把可执行文件塞进内存,把逻辑地址
0x401000转换成真实的物理地址(比如0x7f3a81201000),这时候你的程序才真正获得了在内存中运行的资格。
- 编写一段程序并保存为
三种链接方式
- 静态链接:装入前链接成一个完整装入模块
- 装入时动态链接:运行时边装入边链接
- 运行时动态链接:运行时需要目标模块才装入并链接
三种装入方式
- 绝对装入:编译时产生绝对地址
- 可重定位装入:装入时将逻辑地址转换为物理地址
- 动态运行时装入:运行时将逻辑地址转换为物理地址,需设置重定位寄存器
内存管理的概念
- 内存空间的分配与回收
- 内存空间的扩充(实现虚拟性)
- 地址转换
- 操作系统负责实现逻辑地址到物理地址的转换(这个过程称为==地址重定位==)
- 三种方式
- 绝对装入:编译时产生绝对地址
- 单道程序阶段,此时还没产生操作系统
- 可重定位装入:装入时将逻辑地址转换为物理地址
- 用于早期的多道批处理操作系统
- 动态运行时装入:运行时将逻辑地址转换为物理地址,需设置1
- 绝对装入:编译时产生绝对地址
- 存储保护
- 保证各进程在自己的内存空间内运行,不会越界访问
- 两种方式
- 设置上下限寄存器
- 利用重定位寄存器、界地址寄存器进行判断
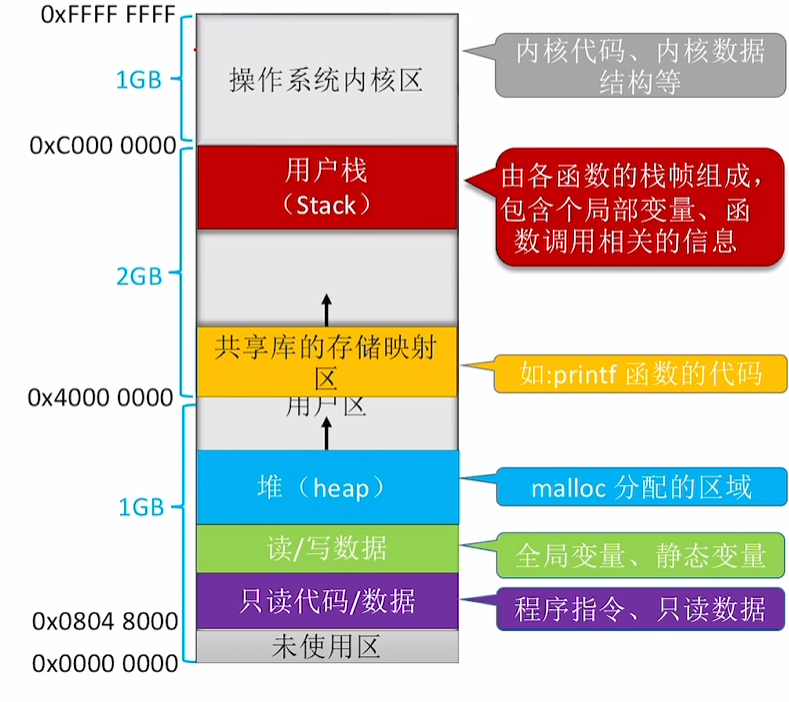
进程的内存映像
操作系统内核区(0xFFFF FFFF - 0xC000 0000)
- 这是内核空间,存放操作系统的核心代码和数据结构
- 用户进程无法直接访问,需要通过系统调用
用户栈区(Stack)(-0xC000 0000)
- 从高地址向低地址增长(图中向下的箭头)
- 存储函数调用的栈帧,包含局部变量、函数参数、返回地址等
- 每次函数调用都会在栈上分配新的栈帧
共享库的存储映射区/用户区(0x4000 0000-)
- 存放动态链接库(如printf函数的代码)
- 这个区域可以被多个进程共享,节省内存
堆区(Heap)
- 从低地址向高地址增长(图中向上的箭头)
- 用于动态内存分配,如malloc分配的内存
- 大小可以在运行时调整
读/写数据段
- 存储已初始化的全局变量和静态变量
- 程序运行时可以修改这些数据
只读代码/数据段(0x0804 8000附近)
- 存储程序的机器指令和只读数据
- 这个区域通常是不可写的,防止程序意外修改自己的代码
未使用区(0x0000 0000)
- 最低地址区域,通常不使用
- 访问这个区域会导致段错误
连续分配的管理方式
为用户进程分配的必须是一个连续的内存空间
- 单一连续分配
- 只支持单道程序,内存分为系统区和用户区,用户程序放在用户区
- 无外部碎片,有内部碎片
- 固定分区分配
- 支持多道程序,内存用户空间分为若干个固定大小的分区,每个分区只能装一道作业
- 无外部碎片,有内部碎片
- 两种分区方式
- 分区大小相等
- 分区大小不等
- 动态分区分配
- 支持多道程序,在进程装入内存时,根据进程的大小动态地建立分区
- 无内部碎片,有外部碎片
- 外部碎片可用“紧凑”技术来解决
- 回收内存分区时,可能遇到四种情况(总之,相邻的空闲分区要合并)
- 回收区之后有相邻的空闲分区
- 回收区之前有相邻的空闲分区
- 回收区前、后都有相邻的空闲分区
- 回收区前、后都没有相邻的空闲分区
动态分区分配算法
- 首次适应
- 思想:从头到尾找适合的分区
- 分区排列顺序:空闲分区以地址递增次序排列
- 优点
- 综合看==性能最好==
- ==算法开销小==,回收分区后一般不需要对空闲分区队列重新排序
- 最佳适应
- 思想:优先使用更小的分区,以保留更多大分区
- 分区排列顺序:空闲分区以容量递增次序排列
- 优点:会有更多大分区保留下来,更能满足大进程需求
- 缺点:
- 会产生很多太小的、难以利用的碎片
- ==算法开销大==,回收分区后可能需要对空闲分区队列重新排序
- 最坏适应
- 思想:优先使用更大的分区,以防止产生太小的不可用的碎片
- 分区排列顺序:空闲分区以容量递减次序排列
- 优点:可以减少难以利用的小碎片
- 缺点:
- 大分区容易被用完,不利于大进程
- ==算法开销大==(原因同上)
- 邻近适应
- 思想:由首次适应演变而来,每次从上次查找结束位置开始查找
- 分区排列顺序:空闲分区以地址递增次序排列(可排列成循环列表)
- 优点
- 不用每次都从低地址的小分区开始检索
- ==算法开销小==(原因同首次适应算法)
- 缺点:会使高地址的大分区也被用完
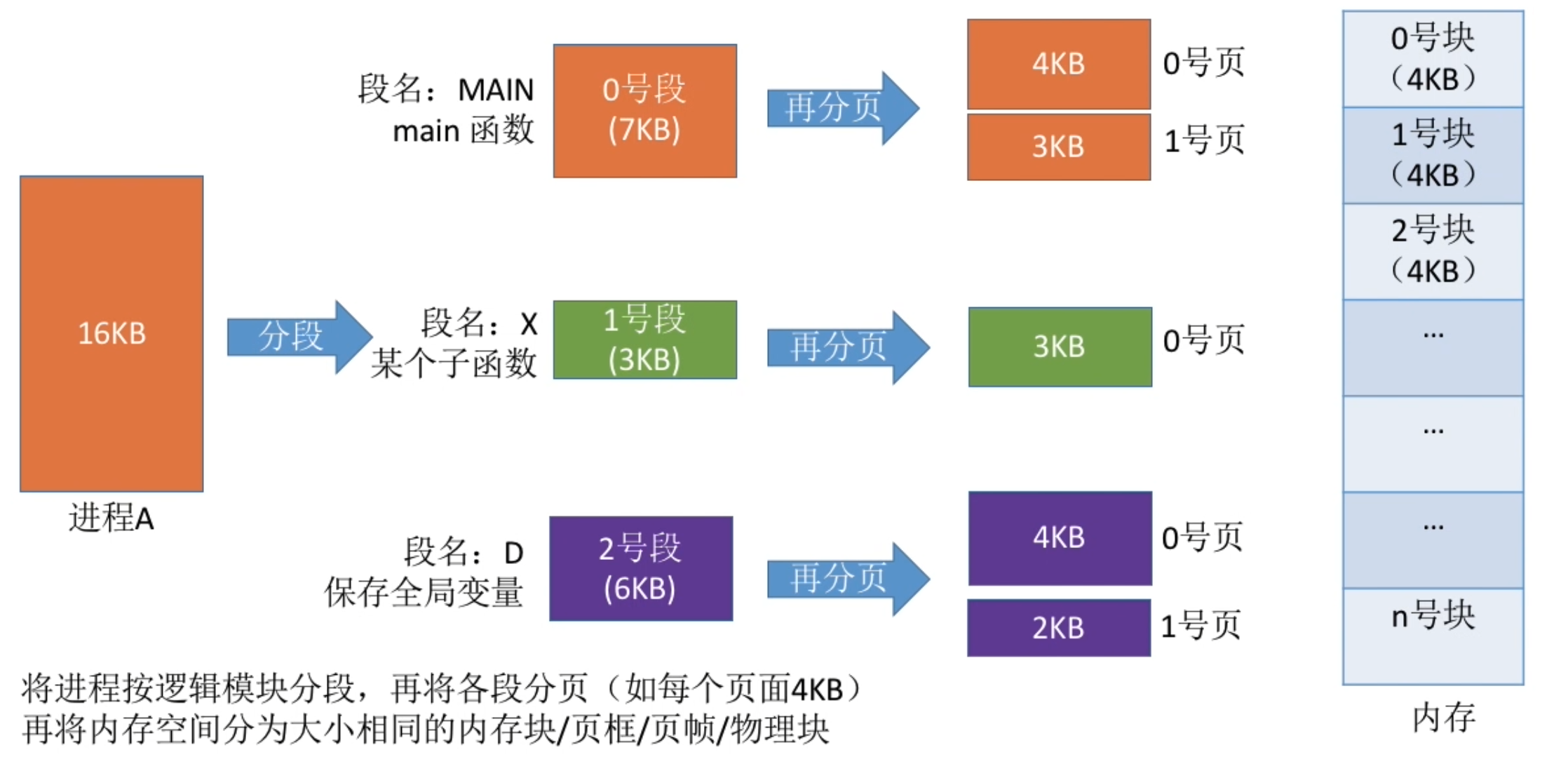
基本分页存储管理的基本概念
- 基本分页存储管理的思想:把进程分页、各个页面可离散地放到各个的内存块中
- 易混概念
- “页框、页帧、内存块、物理块、物理页” vs “页、页面”
- “页框号、页帧号、内存块号、物理块号、物理页号” vs “页号、页面号”
- 页表
- 页表记录了页面和实际存放的内存块之间的映射关系
- 一个进程对应一张页表,进程的每一页对应一个页表项,每个页表项由“页号”和“块号”组成
- 每个页表项的大小是相同的,页号是“隐含”的
- i号页表项存放地址 = 页表始址 + i * 页表项大小
- 逻辑地址结构——可拆分为[页号P, 页内偏移量W]
- 页号 = 逻辑地址 / 页面大小
- 页内偏移量 = 逻辑地址 % 页面大小
- 如何实现地址转换
- 计算出逻辑地址对应的[页号, 页内偏移量]
- 找到对应页面在内存中的存放位置(查页表)
- 物理地址 = 页面始址 + 页内偏移量
基本地址变换机构
- 页表寄存器的作用
- 存放页表起始位置
- 存放页表长度
- 地址变换过程
- 根据逻辑地址算出页号、页内偏移量
- 页号的合法性检查(与页表长度对比)
- 若页号合法,再根据页表起始地址、页号找到对应页表项(第一次访问内存:查页表)
- 根据页表项中记录的内存块号、页内偏移量得到最终的物理地址
- 访问物理内存对应的内存单元(第二次访问内存:访问目标内存单元)
- 其他小细节
- 页内偏移量位数与页面大小之间的关系(要能用其中一个条件推出另一个条件)
- 页式管理中地址是一维的
- 实际应用中,通常使一个页框恰好能放入整数个页表项
- 为了方便找到页表项,页表一般是放在连续的内存块中的
具有快表的地址变换机构
- 基本地址变换机构
- 地址变换过程
- 算页号、页内偏移量
- 检查页号合法性
- 查页表,找到页面存放的内存块号
- 根据内存块号与页内偏移量得到物理地址
- 访问目标内存单元
- 访问一个逻辑地址的访存次数
- 两次访存
- 地址变换过程
- 具有快表的地址变换机构
- 地址变换过程
- 算页号、页内偏移量
- 检查页号合法性
- ==查快表==。若命中,即可知道页面存放的内存块号,可直接进行
5。若未命中则进行4 - 查页表,找到页面存放的内存块号,==并且将页表项复制到快表中==
- 根据内存块号与页内偏移量得到物理地址
- 访问目标内存单元
- 访问一个逻辑地址的访存次数
- 快表==命中==,只需==一次访存==
- 快表==未命中==,需要==两次访存==
- 地址变换过程
TLB与普通Cache的区别:TLB中只有页表项的副本,而普通Cache中可能会有其他各种数据的副本
两级页表
单级页表存在的问题
- 所有页表项必须连续存放,页表过大时需要很大的连续空间
- 在一段时间内并非所有页面都用得到,因此没必要让整个页表常驻内存
两级页表
- 将长长的页表再分页
- 逻辑地址结构:(一级页号, 二级页号, 页内偏移量)
- 注意几个术语:页目录表/外层页表/顶级页表
如何实现地址变换
- 按照地址结构将逻辑地址拆分成三部分
- 从PCB中读出页目录表始址,根据一级页号查找目录表,找到下一级页表在内存忠的存放地址
- 根据二级页号查表,找到最终想访问的内存块号
- 结合页内偏移量得到物理地址
几个细节
- 多级页表中。各级页表的大小不能超过一个页面。若两级页表不够,可以分更多级
- 多级页表的访问次数(假设没有快表机构)——N级页表访问一个逻辑地址需要N+1次访存

基本分段存储管理方式
- 分段
- 将地址空间按照程序自身的逻辑关系划分为若干段,每段从0开始编址
- 每个段在内存中占据连续空间,但各段之间可以不相邻
- 逻辑地址结构:(段号, 段内地址)
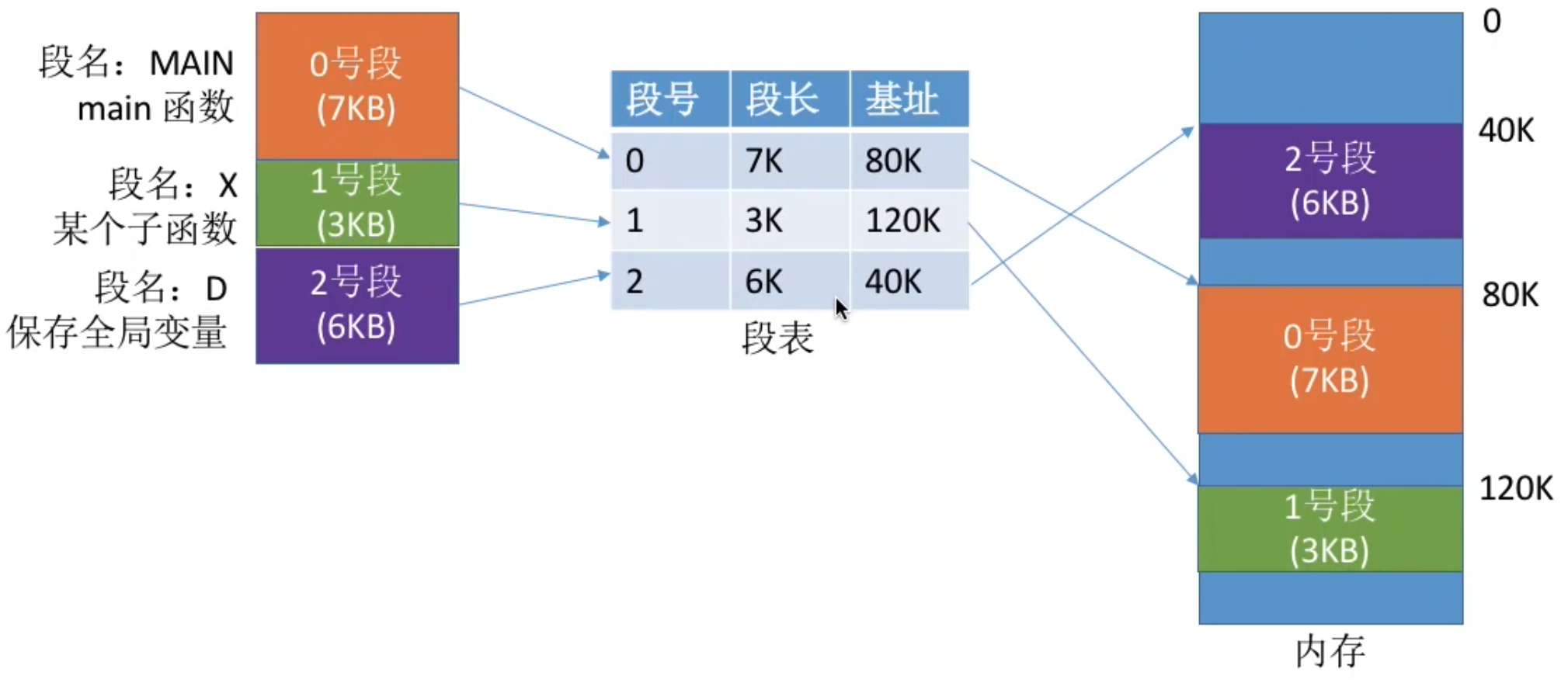
- 段表
- 记录逻辑段到实际存储地址的映射关系
- 每个段对应一个段表项。各段表项长度相同,由段号(隐含)、段长、基址组成
- 地址变换
- 由逻辑地址得到段号、段内地址
- 段号与段表寄存器中的段长度比较,检查是否越界
- 由段表始址、段号找到对应段表项
- 根据段表中记录的段长,检查段内地址是否越界
- 由段表中的“基址+段内地址”得到最终的
- 访问目标单元
- 分段 vs 分页
- 分页对用户不可见,分段对用户可见
- 分页的地址空间是一维的,分段的地址空间是二维的
- 分段更容易实现信息的共享和保护(纯代码/可重入代码可以共享)
- 分页(单级页表)、分段访问一个逻辑地址都需要两次访存,分段存储中也可以引入快表机构
段页式管理方式
- 分段+分页
- 将地址空间按照程序自身的逻辑关系划分为若干个段,在将各段分为大小相等的页面
- 将内存空间分为与页面大小相等的一个个内存块,系统以块为单位为进程分配内存
- 逻辑地址结构:(段号, 页号, 页内偏移量)
- 段表、页表
- 每个段对应一个段表项。各段表项长度相同,由段号(隐含)、页表长度、页表存放地址组成
- 每个页对应一个页表项。各页表项长度相同,由页号(隐含)、页面存放的内存块号组成
- 地址变换
- 由逻辑地址得到段号、页号、页内偏移量
- 段号与段表寄存器中的段长度比较,检查是否越界
- 由段表始址、段号找到对应段表项
- 根据段表中记录的页表长度,检查页号是否越界
- 由段表中的页表地址、页号查询页表,找到相应页表项
- 由页面存放的内存块号、页内偏移量得到最终的物理地址
- 访问目标单元
- 访问一个逻辑地址所需访存次数
- 第一次——查段表、第二次——查页表、第三次——访问目标单元
- 可引入快表机构,以段号和页号为关键字查询快表,即可直接找到最终的目标页面存放位置。引入快表后仅需一次访存
虚拟内存的基本概念
- 传统存储管理方式的特征、缺点
- 一次性:作业数据必须一次全部调入内存
- 驻留性:作业数据在整个运行期间都会常驻内存
- 局部性原理
- 时间局部性:现在访问的指令、数据在不久后很可能会被再次访问
- 空间局部性:现在访问的内存单元周围的内存空间,很可能在不久后会被访问
- 高速缓存技术:使用频繁的数据放到更高速的存储器中
- 虚拟内存的定义和特征
- 程序不需全部装入即可运行,运行时根据需要动态调入数据,若内存不够,还需换出一些数据
- 特征
- 多次性:无需在作业运行时一次性全部装入内存,而是允许被分成多次调入内存
- 对调性:无需在作业运行时一直常驻内存,而是允许在作业运行过程中,将作业换入、换出
- 虚拟性:从逻辑上扩充了内存的容量,使用户看到的内存容量,远大于实际的容量
- 如何实现虚拟内存技术
- 访问的信息不在内存时,由操作系统负责将所需信息从外存调入内存(==请求调页功能==)
- 内存空间不够时,将内存中暂时用不到的信息换出到外存(==页面置换功能==)
- 虚拟内存的实现
- 请求分页存储管理
- 请求分段存储管理
- 请求段页式存储管理
请求分页管理方式
- 页表机制
- 在基本分页的基础上增加了几个表项
- 状态位:表示页面是否已在内存中
- 访问字段:记录最近被访问过几次,或记录上次访问的时间,供置换算法选择换出页面时参考
- 修改位:表示页面调入内存后是否被修改过,只有被修改过的页面才需在置换时写回外存
- 外存地址:页面在外存中存放的位置
- 缺页中断机制
- 找到页表项后检查页面是否已在内存,若没在内存,产生缺页中断
- 缺页中断处理中,需要将目标页面调入内存,有必要时还要换出页面
- 缺页中断属于内中断,属于内中断中的“故障”,即可能被系统修复的异常
- 一条指令在执行过程中可能产生多次缺页中断
- 地址变换机构
- 找到页表项时需要检查页面是否在内存中
- 若页面不在内存中,需要请求调页
- 若内存空间不够,还需换出页面
- 页面调入内存后,需要修改相应页表项
页面置换算法
OPT
- 算法规则:优先淘汰最长时间内不会被访问的页面
- 优点
- 缺页率最小
- 性能最好
- 缺点:无法实现
FIFO
- 算法规则:优先淘汰最先进入内存的页面
- 优点:实现简单
- 缺点:性能很差,可能出现Belady^1异常
LRU
- 算法规则:优先淘汰最近最久没访问的页面
- 优点:性能很好
- 缺点:需要硬件支持,算法开销大
CLOCK(NRU)
- 算法规则:
- 循环扫描各页面
- 第一轮淘汰访问位=0的,并将扫描过的页面访问位改为1.若第一轮没选中,则进行第二轮扫描
- 优点:实现简单,算法开销小
- 缺点:未考虑页面是否被修改过
- 算法规则:
改进型CLOCK(改进型NRU)
- 算法规则:
- 若用(访问位, 修改位)的形式表述,则
- 第一轮:淘汰(0, 0)
- 第二轮:淘汰(0, 1),并将扫描过的页面访问位都置为0
- 第三轮:淘汰(0, 0)
- 第四轮:淘汰(0, 1)
- 优点:算法开销小,性能也不错
第一优先级:最近没访问,且没修改的页面
第二优先级:最近没访问,但修改过的页面
第三优先级:最近访问过,但没修改的页面
第四优先级:最近访问过,且修改过的页面
- 算法规则:
页面分配策略
- 驻留集:指请求分页存储管理中给进程分配的内存块的集合
- 页面分配、置换策略
- 固定分配 vs 可变分配:区别在于进程运行期间驻留集大小是否可变
- 局部置换 vs 全局置换:区别在于发生缺页时是否只能从进程自己的页面中选择一个换出
- 固定分配局部置换:进程运行前就分配一定数量物理块,缺页时只能换出进程自己的某一页
- 可变分配全局置换:只要缺陷就分配新物理块,可能来自空闲物理块,也可能需换出别的进程页面
- 可变分配局部置换:频繁换页的进程,多分配一些物理块;缺页率很低的进程,回收一些物理块。直到缺页率合适
- 何时调入页面
- 预调页策略:一般用于进程运行前
- 请求调页策略:进程运行时,发现缺页再调页
- 从何处调页
- ==对换区==——采用连续存储方式,速度更快;==文件区==——采用离散存储方式,速度更慢
- 对换区足够大:运行将数据从文件区复制到对换区,之后所有的页面调入、调出都是在内存与对换区之间进行
- 对换区不够大:不会修改的数据每次都从文件区调入;会修改的数据调出到对换区,需要时再从对换区调入
- UNIX方式:第一次使用的页面都从文件区调入;调出的页面都写回对换区,再次使用时从对换区调入
- 抖动(颠簸)现象
- 页面频繁换入换出的现象
- 主要原因是分配给进程的物理块不够
- 工作集:
- 在某段时间间隔里,进程实际访问页面的集合。
- 驻留集大小一般不能小于工作及大小
内存映射文件
- 特性
- 进程可使用系统调用,请求操作系统将文件映射到进程的虚拟地址空间
- 以访问内存的方式读写文件
- 进程关闭文件时,操作系统负责将文件数据写回磁盘,并解除内存映射
- 多个进程可以映射同一个文件,方便共享
- 优点
- 程序员编程简单,已建立映射的文件,只需按访问内存的方式读写即可
- 文件数据的读入/写出完全由操作系统负责,I/O效率可以由操作系统负责优化